This is the multi-page printable view of this section. Click here to print.
GUIDES
1 - HugeGraph Architecture Overview
1 概述
作为一套覆盖图数据库、图计算与图 AI 的全栈图系统,HugeGraph 以高性能图引擎(HugeGraph Server)为核心,支持 OLTP 和 OLAP 两种图计算类型。其中 OLTP 层实现了 Apache TinkerPop3 框架,支持 Gremlin 和 Cypher 查询语言,拥有功能齐全的应用工具链,还提供了插件式后端存储驱动框架。
下面是 HugeGraph 的整体架构图:
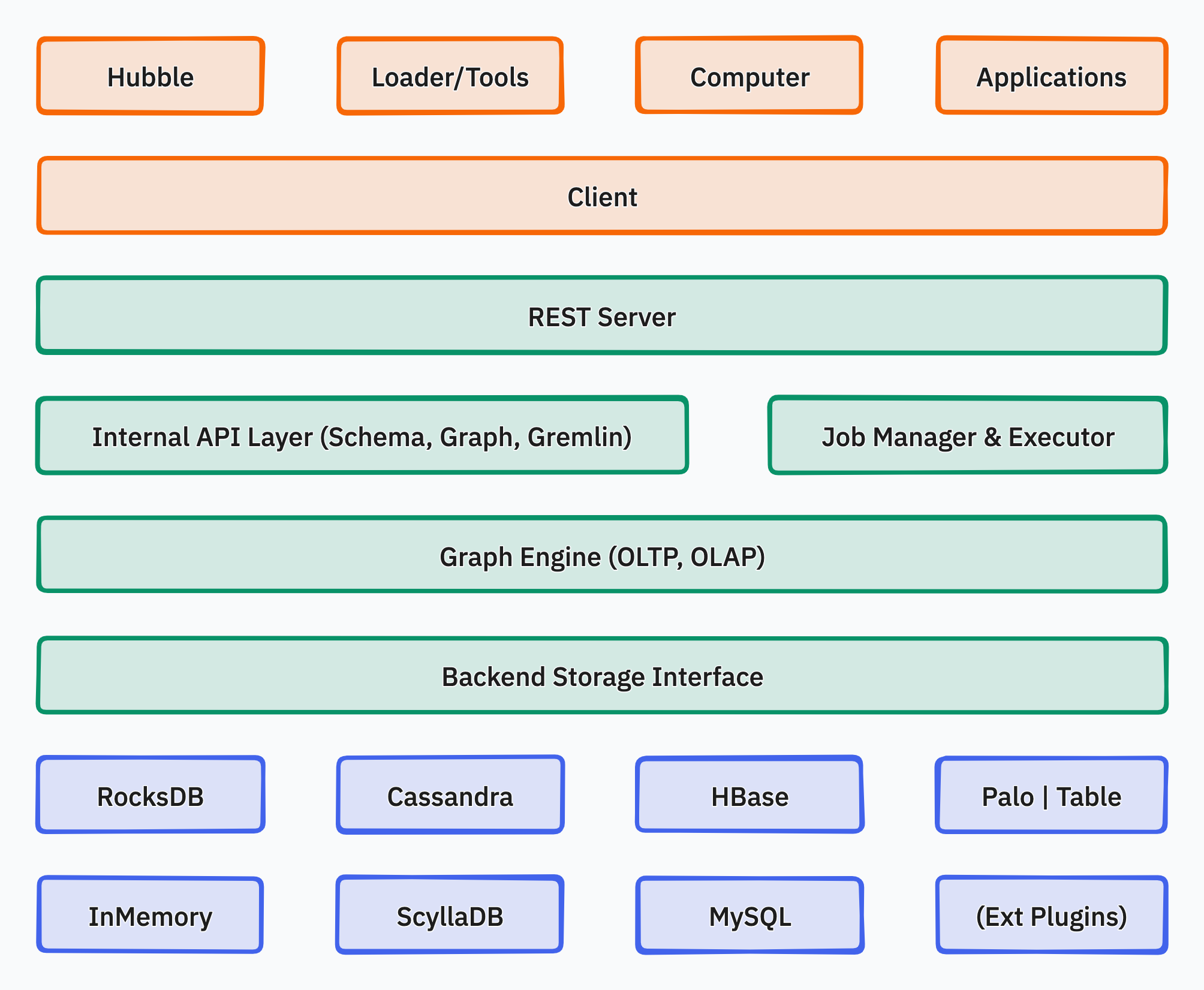
HugeGraph 包括三个层次的功能,分别是应用程序层、图引擎层和存储层。
- 应用程序层:
- Hubble: 一站式可视化分析平台,平台涵盖了从数据建模,到数据快速导入,再到数据的在线、离线分析、以及图的统一管理的全过程,实现了图应用的全流程向导式操作。
- Loader: 数据导入组件,能够将多种数据源的数据转化为图的顶点和边并批量导入到图数据库中。
- Tools: 命令行工具,用于部署、管理和备份/恢复 HugeGraph 中的数据。
- Computer: 分布式图处理系统 (OLAP),它是 Pregel 的一个实现,可以运行在 Kubernetes 上。
- Client: 使用 Java 编写的 HugeGraph 客户端,用户可以使用 Client 编写 Java 代码操作 HugeGraph,后续可根据需要提供 Python、Go、C++ 等多语言支持。
- 图引擎层:
- REST Server: 提供 RESTful API 用于查询 Graph/Schema 等信息,支持 Gremlin 和 Cypher 查询语言,提供服务监控和运维的 APIs。
- Graph Engine: 支持 OLTP 和 OLAP 两种图计算类型,其中 OLTP 实现了 Apache TinkerPop3 框架。
- Backend Interface: 实现将图数据存储到后端。
- 存储层:
- Storage Backend: 支持多种内置存储后端 (RocksDB/MySQL/HBase/…),也允许用户无需更改现有源码的情况下扩展自定义后端。
2 - HugeGraph Design Concepts
1. Property Graph
常见的图数据表示模型有两种,分别是RDF(Resource Description Framework)模型和属性图(Property Graph)模型。 RDF和Property Graph都是最基础、最有名的图表示模式,都能够表示各种图的实体关系建模。 RDF是W3C标准,而Property Graph是工业标准,受到广大图数据库厂商的广泛支持。HugeGraph目前采用Property Graph。
HugeGraph对应的存储概念模型也是参考Property Graph而设计的,具体示例详见下图:(此图为旧版设计已过时,请忽略它,后续更新)
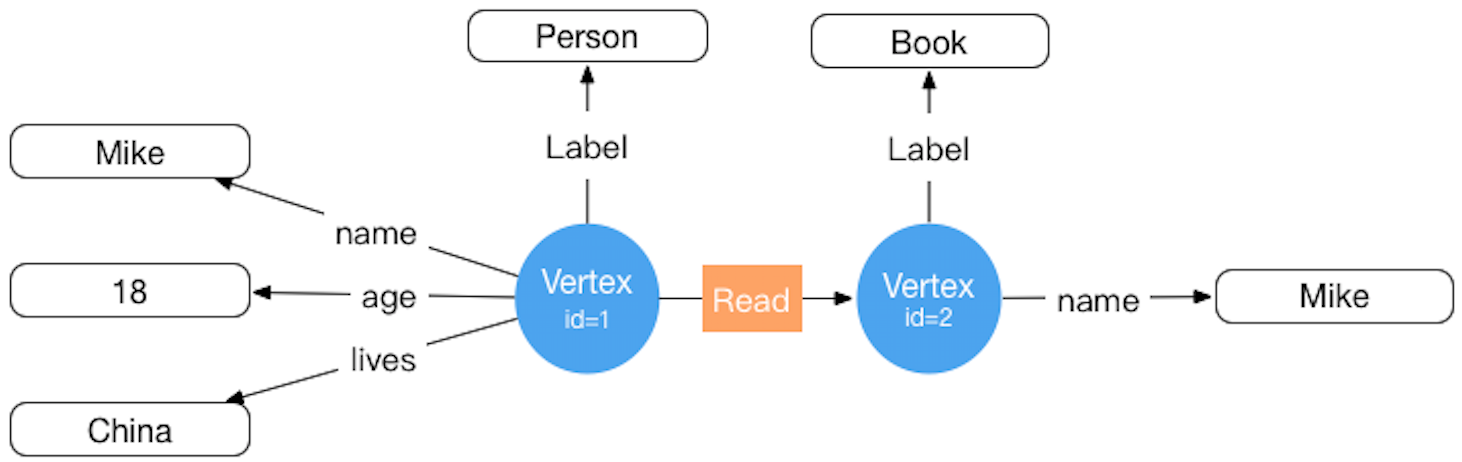
在HugeGraph内部,每个顶点 / 边由唯一的 VertexId / EdgeId 标识,属性存储在对应点 / 边内部。而顶点与顶点之间的关系 / 映射则是通过边来存储的。
顶点属性值通过边指针方式存储时,如果要更新一个顶点特定的属性值直接通过覆盖写入即可,其弊端是冗余存储了VertexId; 如果要更新关系的属性需要通过read-and-modify方式,先读取所有属性,修改部分属性,然后再写入存储系统,更新效率较低。 从经验来看顶点属性的修改需求较多,而边的属性修改需求较少,例如PageRank和Graph Cluster等计算都需要频繁修改顶点的属性值。
2. 图分区方案
对于分布式图数据库而言,图的分区存储方式有两种:分别是边分割存储(Edge Cut)和点分割存储(Vertex Cut),如下图所示。 使用Edge Cut方式存储图时,任何一个顶点只会出现在一台机器上,而边可能分布在不同机器上,这种存储方式有可能导致边多次存储。 使用Vertex Cut方式存储图时,任何一条边只会出现在一台机器上,而每相同的一个点可能分布到不同机器上,这种存储方式可能会导致顶点多次存储。
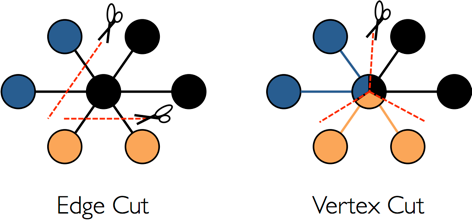
采用EdgeCut分区方案可以支持高性能的插入和更新操作,而VertexCut分区方案更适合静态图查询分析,因此EdgeCut适合OLTP图查询,VertexCut更适合OLAP的图查询。 HugeGraph目前采用EdgeCut的分区方案。
3. VertexId 策略
HugeGraph的Vertex支持三种ID策略,在同一个图数据库中不同的VertexLabel可以使用不同的Id策略,目前HugeGraph支持的Id策略分别是:
- 自动生成(AUTOMATIC):使用Snowflake算法自动生成全局唯一Id,Long类型;
- 主键(PRIMARY_KEY):通过VertexLabel+PrimaryKeyValues生成Id,String类型;
- 自定义(CUSTOMIZE_STRING|CUSTOMIZE_NUMBER):用户自定义Id,分为String和Long类型两种,需自己保证Id的唯一性;
默认的Id策略是AUTOMATIC,如果用户调用primaryKeys()方法并设置了正确的PrimaryKeys,则自动启用PRIMARY_KEY策略。 启用PRIMARY_KEY策略后HugeGraph能根据PrimaryKeys实现数据去重。
- AUTOMATIC ID策略
schema.vertexLabel("person")
.useAutomaticId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- PRIMARY_KEY ID策略
schema.vertexLabel("person")
.usePrimaryKeyId()
.properties("name", "age", "city")
.primaryKeys("name", "age")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- CUSTOMIZE_STRING ID策略
schema.vertexLabel("person")
.useCustomizeStringId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, "123456", "name", "marko","age", 18, "city", "Beijing");
- CUSTOMIZE_NUMBER ID策略
schema.vertexLabel("person")
.useCustomizeNumberId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, 123456, "name", "marko","age", 18, "city", "Beijing");
如果用户需要Vertex去重,有三种方案分别是:
- 采用PRIMARY_KEY策略,自动覆盖,适合大数据量批量插入,用户无法知道是否发生了覆盖行为
- 采用AUTOMATIC策略,read-and-modify,适合小数据量插入,用户可以明确知道是否发生覆盖
- 采用CUSTOMIZE_STRING或CUSTOMIZE_NUMBER策略,用户自己保证唯一
4. EdgeId 策略
HugeGraph的EdgeId是由srcVertexId+edgeLabel+sortKey+tgtVertexId四部分组合而成。其中sortKey是HugeGraph的一个重要概念。
在Edge中加入sortKey作为Edge的唯一标识的原因有两个:
- 如果两个顶点之间存在多条相同Label的边可通过
sortKey来区分 - 对于SuperNode的节点,可以通过
sortKey来排序截断。
由于EdgeId是由srcVertexId+edgeLabel+sortKey+tgtVertexId四部分组合,多次插入相同的Edge时HugeGraph会自动覆盖以实现去重。
需要注意的是如果批量插入模式下Edge的属性也将会覆盖。
另外由于HugeGraph的EdgeId采用自动去重策略,对于self-loop(一个顶点存在一条指向自身的边)的情况下HugeGraph认为仅有一条边,对于采用AUTOMATIC策略的图数据库(例如TitianDB )则会认为该图存在两条边。
HugeGraph的边仅支持有向边,无向边可以创建Out和In两条边来实现。
5. HugeGraph transaction overview
TinkerPop事务概述
TinkerPop transaction事务是指对数据库执行操作的工作单元,一个事务内的一组操作要么执行成功,要么全部失败。 详细介绍请参考TinkerPop官方文档:http://tinkerpop.apache.org/docs/current/reference/#transactions
TinkerPop事务操作接口
- open 打开事务
- commit 提交事务
- rollback 回滚事务
- close 关闭事务
TinkerPop事务规范
- 事务必须显式提交后才可生效(未提交时修改操作只有本事务内查询可看到)
- 事务必须打开之后才可提交或回滚
- 如果事务设置自动打开则无需显式打开(默认方式),如果设置手动打开则必须显式打开
- 可设置事务关闭时:自动提交、自动回滚(默认方式)、手动(禁止显式关闭)等3种模式
- 事务在提交或回滚后必须是关闭状态
- 事务在查询后必须是打开状态
- 事务(非threaded tx)必须线程隔离,多线程操作同一事务互不影响
更多事务规范用例见:Transaction Test
HugeGraph事务实现
- 一个事务中所有的操作要么成功要么失败
- 一个事务只能读取到另外一个事务已提交的内容(Read committed)
- 所有未提交的操作均能在本事务中查询出来,包括:
- 增加顶点能够查询出该顶点
- 删除顶点能够过滤掉该顶点
- 删除顶点能够过滤掉该顶点相关边
- 增加边能够查询出该边
- 删除边能够过滤掉该边
- 增加/修改(顶点、边)属性能够在查询时生效
- 删除(顶点、边)属性能够在查询时生效
- 所有未提交的操作在事务回滚后均失效,包括:
- 顶点、边的增加、删除
- 属性的增加/修改、删除
示例:一个事务无法读取另一个事务未提交的内容
static void testUncommittedTx(final HugeGraph graph) throws InterruptedException {
final CountDownLatch latchUncommit = new CountDownLatch(1);
final CountDownLatch latchRollback = new CountDownLatch(1);
Thread thread = new Thread(() -> {
// this is a new transaction in the new thread
graph.tx().open();
System.out.println("current transaction operations");
Vertex james = graph.addVertex(T.label, "author",
"id", 1, "name", "James Gosling",
"age", 62, "lived", "Canadian");
Vertex java = graph.addVertex(T.label, "language", "name", "java",
"versions", Arrays.asList(6, 7, 8));
james.addEdge("created", java);
// we can query the uncommitted records in the current transaction
System.out.println("current transaction assert");
assert graph.vertices().hasNext() == true;
assert graph.edges().hasNext() == true;
latchUncommit.countDown();
try {
latchRollback.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("current transaction rollback");
graph.tx().rollback();
});
thread.start();
// query none result in other transaction when not commit()
latchUncommit.await();
System.out.println("other transaction assert for uncommitted");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
latchRollback.countDown();
thread.join();
// query none result in other transaction after rollback()
System.out.println("other transaction assert for rollback");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
}
事务实现原理
- 服务端内部通过将事务与线程绑定实现隔离(ThreadLocal)
- 本事务未提交的内容按照时间顺序覆盖老数据以供本事务查询最新版本数据
- 底层依赖后端数据库保证事务原子性操作(如Cassandra/RocksDB的batch接口均保证原子性)
注意
RESTful API暂时未暴露事务接口
TinkerPop API允许打开事务,请求完成时会自动关闭(Gremlin Server强制关闭)
3 - HugeGraph Plugin 机制及插件扩展流程
背景
- HugeGraph 不仅开源开放,而且要做到简单易用,一般用户无需更改源码也能轻松增加插件扩展功能。
- HugeGraph 支持多种内置存储后端,也允许用户无需更改现有源码的情况下扩展自定义后端。
- HugeGraph 支持全文检索,全文检索功能涉及到各语言分词,目前已内置 8 种中文分词器,也允许用户无需更改现有源码的情况下扩展自定义分词器。
可扩展维度
目前插件方式提供如下几个维度的扩展项:
- 后端存储
- 序列化器
- 自定义配置项
- 分词器
插件实现机制
- HugeGraph 提供插件接口 HugeGraphPlugin,通过 Java SPI 机制支持插件化
- HugeGraph 提供了 4 个扩展项注册函数:
registerOptions()、registerBackend()、registerSerializer()、registerAnalyzer() - 插件实现者实现相应的 Options、Backend、Serializer 或 Analyzer 的接口
- 插件实现者实现 HugeGraphPlugin 接口的
register()方法,在该方法中注册上述第 3 点所列的具体实现类,并打成 jar 包 - 插件使用者将 jar 包放在 HugeGraph Server 安装目录的
plugins目录下,修改相关配置项为插件自定义值,重启即可生效
插件实现流程实例
1 新建一个 maven 项目
1.1 项目名称取名:hugegraph-plugin-demo
1.2 添加hugegraph-core Jar 包依赖
maven pom.xml 详细内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.hugegraph</groupId>
<artifactId>hugegraph-plugin-demo</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>hugegraph-plugin-demo</name>
<dependencies>
<dependency>
<groupId>org.apache.hugegraph</groupId>
<artifactId>hugegraph-core</artifactId>
<version>${project.version}</version>
</dependency>
</dependencies>
</project>
2 实现扩展功能
2.1 扩展自定义后端
2.1.1 实现接口 BackendStoreProvider
- 可实现接口:
org.apache.hugegraph.backend.store.BackendStoreProvider - 或者继承抽象类:
org.apache.hugegraph.backend.store.AbstractBackendStoreProvider
以 RocksDB 后端 RocksDBStoreProvider 为例:
public class RocksDBStoreProvider extends AbstractBackendStoreProvider {
protected String database() {
return this.graph().toLowerCase();
}
@Override
protected BackendStore newSchemaStore(String store) {
return new RocksDBSchemaStore(this, this.database(), store);
}
@Override
protected BackendStore newGraphStore(String store) {
return new RocksDBGraphStore(this, this.database(), store);
}
@Override
public String type() {
return "rocksdb";
}
@Override
public String version() {
return "1.0";
}
}
2.1.2 实现接口 BackendStore
BackendStore 接口定义如下:
public interface BackendStore {
// Store name
public String store();
// Database name
public String database();
// Get the parent provider
public BackendStoreProvider provider();
// Open/close database
public void open(HugeConfig config);
public void close();
// Initialize/clear database
public void init();
public void clear();
// Add/delete data
public void mutate(BackendMutation mutation);
// Query data
public Iterator<BackendEntry> query(Query query);
// Transaction
public void beginTx();
public void commitTx();
public void rollbackTx();
// Get metadata by key
public <R> R metadata(HugeType type, String meta, Object[] args);
// Backend features
public BackendFeatures features();
// Generate an id for a specific type
public Id nextId(HugeType type);
}
2.1.3 扩展自定义序列化器
序列化器必须继承抽象类:org.apache.hugegraph.backend.serializer.AbstractSerializer(implements GraphSerializer, SchemaSerializer)
主要接口的定义如下:
public interface GraphSerializer {
public BackendEntry writeVertex(HugeVertex vertex);
public BackendEntry writeVertexProperty(HugeVertexProperty<?> prop);
public HugeVertex readVertex(HugeGraph graph, BackendEntry entry);
public BackendEntry writeEdge(HugeEdge edge);
public BackendEntry writeEdgeProperty(HugeEdgeProperty<?> prop);
public HugeEdge readEdge(HugeGraph graph, BackendEntry entry);
public BackendEntry writeIndex(HugeIndex index);
public HugeIndex readIndex(HugeGraph graph, ConditionQuery query, BackendEntry entry);
public BackendEntry writeId(HugeType type, Id id);
public Query writeQuery(Query query);
}
public interface SchemaSerializer {
public BackendEntry writeVertexLabel(VertexLabel vertexLabel);
public VertexLabel readVertexLabel(HugeGraph graph, BackendEntry entry);
public BackendEntry writeEdgeLabel(EdgeLabel edgeLabel);
public EdgeLabel readEdgeLabel(HugeGraph graph, BackendEntry entry);
public BackendEntry writePropertyKey(PropertyKey propertyKey);
public PropertyKey readPropertyKey(HugeGraph graph, BackendEntry entry);
public BackendEntry writeIndexLabel(IndexLabel indexLabel);
public IndexLabel readIndexLabel(HugeGraph graph, BackendEntry entry);
}
2.1.4 扩展自定义配置项
增加自定义后端时,可能需要增加新的配置项,实现流程主要包括:
- 增加配置项容器类,并实现接口
org.apache.hugegraph.config.OptionHolder - 提供单例方法
public static OptionHolder instance(),并在对象初始化时调用方法OptionHolder.registerOptions() - 增加配置项声明,单值配置项类型为
ConfigOption、多值配置项类型为ConfigListOption
以 RocksDB 配置项定义为例:
public class RocksDBOptions extends OptionHolder {
private RocksDBOptions() {
super();
}
private static volatile RocksDBOptions instance;
public static synchronized RocksDBOptions instance() {
if (instance == null) {
instance = new RocksDBOptions();
instance.registerOptions();
}
return instance;
}
public static final ConfigOption<String> DATA_PATH =
new ConfigOption<>(
"rocksdb.data_path",
"The path for storing data of RocksDB.",
disallowEmpty(),
"rocksdb-data"
);
public static final ConfigOption<String> WAL_PATH =
new ConfigOption<>(
"rocksdb.wal_path",
"The path for storing WAL of RocksDB.",
disallowEmpty(),
"rocksdb-data"
);
public static final ConfigListOption<String> DATA_DISKS =
new ConfigListOption<>(
"rocksdb.data_disks",
false,
"The optimized disks for storing data of RocksDB. " +
"The format of each element: `STORE/TABLE: /path/to/disk`." +
"Allowed keys are [graph/vertex, graph/edge_out, graph/edge_in, " +
"graph/secondary_index, graph/range_index]",
null,
String.class,
ImmutableList.of()
);
}
2.2 扩展自定义分词器
分词器需要实现接口org.apache.hugegraph.analyzer.Analyzer,以实现一个 SpaceAnalyzer 空格分词器为例。
package org.apache.hugegraph.plugin;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
import org.apache.hugegraph.analyzer.Analyzer;
public class SpaceAnalyzer implements Analyzer {
@Override
public Set<String> segment(String text) {
return new HashSet<>(Arrays.asList(text.split(" ")));
}
}
3. 实现插件接口,并进行注册
插件注册入口为HugeGraphPlugin.register(),自定义插件必须实现该接口方法,在其内部注册上述定义好的扩展项。
接口org.apache.hugegraph.plugin.HugeGraphPlugin定义如下:
public interface HugeGraphPlugin {
public String name();
public void register();
public String supportsMinVersion();
public String supportsMaxVersion();
}
并且 HugeGraphPlugin 提供了 4 个静态方法用于注册扩展项:
- registerOptions(String name, String classPath):注册配置项
- registerBackend(String name, String classPath):注册后端(BackendStoreProvider)
- registerSerializer(String name, String classPath):注册序列化器
- registerAnalyzer(String name, String classPath):注册分词器
下面以注册 SpaceAnalyzer 分词器为例:
package org.apache.hugegraph.plugin;
public class DemoPlugin implements HugeGraphPlugin {
@Override
public String name() {
return "demo";
}
@Override
public void register() {
HugeGraphPlugin.registerAnalyzer("demo", SpaceAnalyzer.class.getName());
}
}
4. 配置 SPI 入口
- 确保 services 目录存在:hugegraph-plugin-demo/resources/META-INF/services
- 在 services 目录下建立文本文件:org.apache.hugegraph.plugin.HugeGraphPlugin
- 文件内容如下:org.apache.hugegraph.plugin.DemoPlugin
5. 打 Jar 包
通过 maven 打包,在项目目录下执行命令mvn package,在 target 目录下会生成 Jar 包文件。
使用时将该 Jar 包拷到plugins目录,重启服务即可生效。
4 - HugeGraph工具链本地测试指南
本指南帮助开发者在本地运行 HugeGraph 工具链测试。
1. 核心概念
1.1 核心依赖:HugeGraph Server
工具链的集成测试和功能测试都依赖 HugeGraph Server,包括 Client、Loader、Hubble、Spark Connector、Tools 等组件。
1.2 测试类型
- 单元测试 (Unit Tests):测试单个函数/方法,不依赖外部服务
- API 测试 (ApiTestSuite):测试 API 接口,需要运行中的 HugeGraph Server
- 功能测试 (FuncTestSuite):端到端测试,需要完整的系统环境
2. 环境准备
2.1 系统要求
- 操作系统:Linux / macOS(Windows 使用 WSL2)
- JDK:>= 11,配置好
JAVA_HOME - Maven:>= 3.5
- Python:>= 3.11(仅 Hubble 测试需要)
2.2 克隆代码
git clone https://github.com/${GITHUB_USER_NAME}/hugegraph-toolchain.git
cd hugegraph-toolchain
3. 部署测试环境
方式选择
- 脚本部署(推荐):通过指定 Commit ID 精确控制 Server 版本,避免接口不兼容
- Docker 部署:快速启动,但可能版本滞后导致测试失败
详细安装说明参考 社区文档
3.1 脚本部署(推荐)
参数说明
$COMMIT_ID:指定 Server 源码的 Git Commit ID$DB_DATABASE/$DB_PASS:Loader JDBC 测试用的 MySQL 数据库名和密码
部署步骤
1. 安装 HugeGraph Server
# 设置版本
export COMMIT_ID="master" # 或特定 commit hash,如 "8b90977"
# 执行安装(脚本位于 /assembly/travis/ 目录)
hugegraph-client/assembly/travis/install-hugegraph-from-source.sh $COMMIT_ID
- 默认端口:http 8080, https 8443
- 确保端口未被占用
2. 安装可选依赖
# Hadoop (仅 Loader HDFS 测试需要)
hugegraph-loader/assembly/travis/install-hadoop.sh
# MySQL (仅 Loader JDBC 测试需要)
hugegraph-loader/assembly/travis/install-mysql.sh $DB_DATABASE $DB_PASS
3. 健康检查
curl http://localhost:8080/graphs
# 返回 {"graphs":["hugegraph"]} 表示成功
3.2 Docker 部署
注意:Docker 镜像可能版本滞后,如遇兼容性问题请使用脚本部署
快速启动
docker network create hugegraph-net
docker run -itd --name=server -p 8080:8080 --network hugegraph-net hugegraph/hugegraph:latest
docker-compose 配置(可选)
完整配置示例,包含 Server、MySQL、Hadoop 服务(需要 Docker Compose V2):
version: '3.8'
services:
hugegraph-server:
image: hugegraph/hugegraph:latest # 可以替换为特定版本,或构建自己的镜像
container_name: hugegraph-server
ports:
- "8080:8080" # HugeGraph Server HTTP 端口
environment:
# 根据需要配置HugeGraph Server的参数,例如后端存储
- HUGEGRAPH_SERVER_OPTIONS="-Dstore.backend=rocksdb"
volumes:
# 如果需要持久化数据或挂载配置文件,可以在这里添加卷
# - ./hugegraph-data:/opt/hugegraph/data
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/graphs || exit 1"]
interval: 5s
timeout: 3s
retries: 5
networks:
- hugegraph-net
# 如果需要hugegraph-loader的JDBC测试,可以添加以下服务
# mysql:
# image: mysql:5.7
# container_name: mysql-db
# environment:
# MYSQL_ROOT_PASSWORD: ${DB_PASS:-your_mysql_root_password} # 从环境变量读取,或使用默认值
# MYSQL_DATABASE: ${DB_DATABASE:-hugegraph_test_db} # 从环境变量读取,或使用默认值
# ports:
# - "3306:3306"
# volumes:
# - ./mysql-data:/var/lib/mysql # 数据持久化
# healthcheck:
# test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-p${DB_PASS:-your_mysql_root_password}"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
# 如果需要hugegraph-loader的Hadoop/HDFS测试,可以添加以下服务
# namenode:
# image: johannestang/hadoop-namenode:2.0.0-hadoop2.8.5-java8
# container_name: namenode
# ports:
# - "0.0.0.0:9870:9870"
# - "0.0.0.0:8020:8020"
# environment:
# - CLUSTER_NAME=test-cluster
# - HDFS_NAMENODE_USER=root
# - HADOOP_CONF_DIR=/hadoop/etc/hadoop
# volumes:
# - ./config/core-site.xml:/hadoop/etc/hadoop/core-site.xml
# - ./config/hdfs-site.xml:/hadoop/etc/hadoop/hdfs-site.xml
# - namenode_data:/hadoop/dfs/name
# command: bash -c "if [ ! -d /hadoop/dfs/name/current ]; then hdfs namenode -format; fi && /entrypoint.sh"
# healthcheck:
# test: ["CMD", "hdfs", "dfsadmin", "-report"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
# datanode:
# image: johannestang/hadoop-datanode:2.0.0-hadoop2.8.5-java8
# container_name: datanode
# depends_on:
# - namenode
# environment:
# - CLUSTER_NAME=test-cluster
# - HDFS_DATANODE_USER=root
# - HADOOP_CONF_DIR=/hadoop/etc/hadoop
# volumes:
# - ./config/core-site.xml:/hadoop/etc/hadoop/core-site.xml
# - ./config/hdfs-site.xml:/hadoop/etc/hadoop/hdfs-site.xml
# - datanode_data:/hadoop/dfs/data
# healthcheck:
# test: ["CMD", "hdfs", "dfsadmin", "-report"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
networks:
hugegraph-net:
driver: bridge
volumes:
namenode_data:
datanode_data:
Hadoop 配置挂载
在与 docker-compose.yml 相同的目录下创建 ./config 文件夹用于挂载 Hadoop 配置文件。如果不需要 HDFS 测试,可以跳过此步骤。
📁 ./config/core-site.xml 内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
</configuration>
📁 ./config/hdfs-site.xml 内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
Docker 操作
# 启动服务
docker compose up -d
# 检查状态
docker compose ps
lsof -i:8080 # Server
lsof -i:8020 # Hadoop
lsof -i:3306 # MySQL
# 停止服务
docker compose down
4. 运行测试
各工具的测试流程:
4.1 hugegraph-client
编译
mvn -e compile -pl hugegraph-client -Dmaven.javadoc.skip=true -ntp
依赖服务
启动 HugeGraph Server(参考 第3节)
Server 鉴权配置
注意:Docker 镜像 <= 1.5.0 不支持鉴权测试,需 1.6.0+
ApiTest 需要鉴权配置,使用脚本安装可跳过。使用 Docker 需手动配置:
# 1. 修改鉴权模式
cp conf/rest-server.properties conf/rest-server.properties.backup
sed -i '/^auth.authenticator=/c\auth.authenticator=org.apache.hugegraph.auth.StandardAuthenticator' conf/rest-server.properties
grep auth.authenticator conf/rest-server.properties
# 2. 设置密码
# 注:测试代码中默认使用 "pa" 作为密码,设置时需与测试保持一致
bin/stop-hugegraph.sh
export PASSWORD="pa" # 设置为测试默认密码
echo -e "${PASSWORD}" | bin/init-store.sh
bin/start-hugegraph.sh
运行测试
# 检查环境
curl http://localhost:8080/graphs # 应返回 {"graphs":["hugegraph"]}
curl -u admin:pa http://localhost:8080/graphs # 鉴权测试(密码 pa 是测试默认值)
# 运行测试
cd hugegraph-client
mvn test -Dtest=UnitTestSuite -ntp # 单元测试
mvn test -Dtest=ApiTestSuite -ntp # API测试(需 Server)
mvn test -Dtest=FuncTestSuite -ntp # 功能测试(需 Server)
测试失败时检查 Server 日志:
logs/hugegraph-server.log
4.2 hugegraph-loader
编译
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
依赖服务
- 必需:HugeGraph Server
- 可选:Hadoop (HDFS 测试)、MySQL (JDBC 测试)
运行测试
cd hugegraph-loader
mvn test -P unit -ntp # 单元测试
mvn test -P file -ntp # 文件测试(需 Server)
mvn test -P hdfs -ntp # HDFS测试(需 Server + Hadoop)
mvn test -P jdbc -ntp # JDBC测试(需 Server + MySQL)
mvn test -P kafka -ntp # Kafka测试(需 Server)
4.3 hugegraph-hubble
编译
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
cd hugegraph-hubble
mvn -e compile -Dmaven.javadoc.skip=true -ntp
依赖服务
1. 启动 Server(参考 第3节)
2. Python 环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
python -m pip install -r hubble-dist/assembly/travis/requirements.txt
3. 构建并验证
mvn package -Dmaven.test.skip=true
# 可选:启动验证
# 兼容历史(-incubating-)与毕业后 TLP 命名
cd apache-hugegraph-hubble*/bin
./start-hubble.sh -d && sleep 10
curl http://localhost:8088/api/health
./stop-hubble.sh
运行测试
# 单元测试
mvn test -P unit-test -pl hugegraph-hubble/hubble-be -ntp
# API测试(需 Server + Hubble 运行)
curl http://localhost:8080/graphs # 检查 Server
curl http://localhost:8088/api/health # 检查 Hubble
cd hugegraph-hubble/hubble-dist
./assembly/travis/run-api-test.sh
4.4 hugegraph-spark-connector
编译
mvn install -pl hugegraph-client,hugegraph-spark-connector -am -Dmaven.javadoc.skip=true -DskipTests -ntp
运行测试
cd hugegraph-spark-connector
mvn test -ntp # 需 Server 运行
4.5 hugegraph-tools
编译
mvn install -pl hugegraph-client,hugegraph-tools -am -Dmaven.javadoc.skip=true -DskipTests -ntp
运行测试
cd hugegraph-tools
mvn test -Dtest=FuncTestSuite -ntp # 需 Server 运行
5. 常见问题
服务连接问题
症状:无法连接 Server/MySQL/Hadoop
排查:
- 确认服务已启动(Server 必须在 8080 端口)
- 检查端口占用:
lsof -i:8080 - Docker 检查:
docker compose ps和docker compose logs
配置问题
症状:找不到文件、参数错误
排查:
- 检查环境变量:
echo $COMMIT_ID - 脚本权限:
chmod +x hugegraph-*/assembly/travis/*.sh
HDFS 测试失败
排查:
- 确认 NameNode/DataNode 运行正常
- 检查 Hadoop 日志
- 验证 HDFS 连接:
hdfs dfsadmin -report
JDBC 测试失败
排查:
- 确认 MySQL 运行正常
- 验证数据库连接:
mysql -u root -p$DB_PASS - 检查 MySQL 日志
6. 参考资料
- HugeGraph GitHub 仓库:https://github.com/apache/hugegraph
- HugeGraph 工具链 GitHub 仓库:https://github.com/apache/hugegraph-toolchain
- HugeGraph Server 官方文档:https://hugegraph.apache.org/cn/docs/quickstart/hugegraph/hugegraph-server/
- CI 脚本路径:
.github/workflows/*-ci.yml(HugeGraph 工具链项目中的 CI 配置文件,可作为参考) - 依赖服务安装脚本:
hugegraph-*/assembly/travis/(HugeGraph 工具链项目中用于 CI 和本地测试的安装脚本,可直接使用或作为参考)
5 - Backup Restore
描述
Backup 和 Restore 是备份图和恢复图的功能。备份和恢复的数据包括元数据(schema)和图数据(vertex 和 edge)。
Backup
将 HugeGraph 系统中的一张图的元数据和图数据以 JSON 格式导出。
Restore
将 Backup 导出的JSON格式的数据,重新导入到 HugeGraph 系统中的一个图中。
Restore 有两种模式:
- Restoring 模式,将 Backup 导出的元数据和图数据原封不动的恢复到 HugeGraph 系统中。可用于图的备份和恢复,一般目标图是新图(没有元数据和图数据)。比如:
- 系统升级,先备份图,然后升级系统,最后将图恢复到新的系统中
- 图迁移,从一个 HugeGraph 系统中,使用 Backup 功能将图导出,然后使用 Restore 功能将图导入另一个 HugeGraph 系统中
- Merging 模式,将 Backup 导出的元数据和图数据导入到另一个已经存在元数据或者图数据的图中,过程中元数据的 ID 可能发生改变,顶点和边的 ID 也会发生相应变化。
- 可用于合并图
使用方法
可以使用hugegraph-tools进行图的备份和恢复。
Backup
bin/hugegraph backup -t all -d data
该命令将 http://127.0.0.1 的 hugegraph 图的全部元数据和图数据备份到data目录下。
Backup 在三种图模式下都可以正常工作
Restore
Restore 有两种模式: RESTORING 和 MERGING,备份之前首先要根据需要设置图模式。
步骤1:查看并设置图模式
bin/hugegraph graph-mode-get
该命令用于查看当前图模式,包括:NONE、RESTORING、MERGING。
bin/hugegraph graph-mode-set -m RESTORING
该命令用于设置图模式,Restore 之前可以设置成 RESTORING 或者 MERGING 模式,例子中设置成 RESTORING。
步骤2:Restore 数据
bin/hugegraph restore -t all -d data
该命令将data目录下的全部元数据和图数据重新导入到 http://127.0.0.1 的 hugegraph 图中。
步骤3:恢复图模式
bin/hugegraph graph-mode-set -m NONE
该命令用于恢复图模式为 NONE。
至此,一次完整的图备份和图恢复流程结束。
帮助
备份和恢复命令的详细使用方式可以参考hugegraph-tools文档。
Backup/Restore使用和实现的API说明
Backup
Backup 使用元数据和图数据的相应的 list(GET) API 导出,并未增加新的 API。
Restore
Restore 使用元数据和图数据的相应的 create(POST) API 导入,并未增加新的 API。
Restore 时存在两种不同的模式: Restoring 和 Merging,另外,还有常规模式 NONE(默认),区别如下:
- None 模式,元数据和图数据的写入属于正常状态,可参见功能说明。特别的:
- 元数据(schema)创建时不允许指定 ID
- 图数据(vertex)在 id strategy 为 Automatic 时,不允许指定 ID
- Restoring 模式,恢复到一个新图中,特别的:
- 元数据(schema)创建时允许指定 ID
- 图数据(vertex)在 id strategy 为 Automatic 时,允许指定 ID
- Merging 模式,合并到一个已存在元数据和图数据的图中,特别的:
- 元数据(schema)创建时不允许指定 ID
- 图数据(vertex)在 id strategy 为 Automatic 时,允许指定 ID
正常情况下,图模式为 None,当需要 Restore 图时,需要根据需要临时修改图模式为 Restoring 模式或者 Merging 模式,并在完成 Restore 时,恢复图模式为 None。
实现的设置图模式的 RESTful API 如下:
查看某个图的模式. 该操作需要管理员权限
Method & Url
GET http://localhost:8080/graphs/{graph}/mode
Response Status
200
Response Body
{
"mode": "NONE"
}
合法的图模式包括:NONE,RESTORING,MERGING
设置某个图的模式. 该操作需要管理员权限
Method & Url
PUT http://localhost:8080/graphs/{graph}/mode
Request Body
"RESTORING"
合法的图模式包括:NONE,RESTORING,MERGING
Response Status
200
Response Body
{
"mode": "RESTORING"
}
6 - FAQ
如何选择后端存储? 选 RocksDB 还是分布式存储?
HugeGraph 支持多种部署模式,根据数据规模和场景选择:
- 单机模式:Server + RocksDB,适合开发测试和中小规模数据(< 4TB)
- 分布式模式:HugeGraph-PD + HugeGraph-Store (HStore),支持水平扩展和高可用(< 1000TB 数据规模),适合生产环境和大规模图数据应用
注:Cassandra、HBase、MySQL 等后端仅在 HugeGraph <= 1.5 版本中可用,官方后续不再单独维护
启动服务时提示:
xxx (core dumped) xxx请检查JDK版本是否为 Java11 (至少是Java8)
启动服务成功了,但是操作图时有类似于"无法连接到后端或连接未打开"的提示
第一次启动服务前,需要先使用
init-store初始化后端,后续版本会将提示得更清晰直接。所有的后端在使用前都需要执行
init-store吗,序列化的选择可以随意填写么?除了
memory不需要,其他后端均需要,如:cassandra、hbase和rocksdb等,序列化需一一对应不可随意填写。执行
init-store报错:Exception in thread "main" java.lang.UnsatisfiedLinkError: /tmp/librocksdbjni3226083071221514754.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.10' not found (required by /tmp/librocksdbjni3226083071221514754.so)RocksDB需要 gcc 4.3.0 (GLIBCXX_3.4.10) 及以上版本
执行
init-store.sh时报错:NoHostAvailableExceptionNoHostAvailableException是指无法连接到Cassandra服务,如果确定是要使用cassandra后端,请先安装并启动这个服务。至于这个提示本身可能不够直白,我们会更新到文档进行说明的。bin目录下包含start-hugegraph.sh、start-restserver.sh和start-gremlinserver.sh三个似乎与启动有关的脚本,到底该使用哪个自0.3.3版本以来,已经把 GremlinServer 和 RestServer 合并为 HugeGraphServer 了,使用
start-hugegraph.sh启动即可,后两个在后续版本会被删掉。配置了两个图,名字是
hugegraph和hugegraph1,而启动服务的命令是start-hugegraph.sh,是只打开了hugegraph这个图吗start-hugegraph.sh会打开所有gremlin-server.yaml的graphs下的图,这二者并无名字上的直接关系服务启动成功后,使用
curl查询所有顶点时返回乱码服务端返回的批量顶点/边是压缩(gzip)过的,可以使用管道重定向至
gunzip进行解压(curl http://example | gunzip),也可以用Firefox的postman或者Chrome浏览器的restlet插件发请求,会自动解压缩响应数据。使用顶点Id通过
RESTful API查询顶点时返回空,但是顶点确实是存在的检查顶点Id的类型,如果是字符串类型,
API的url中的id部分需要加上双引号,数字类型则不用加。已经根据需要给顶点Id加上了双引号,但是通过
RESTful API查询顶点时仍然返回空检查顶点id中是否包含
+、空格、/、?、%、&和=这些URL的保留字符,如果存在则需要进行编码。下表给出了编码值:特殊字符 | 编码值 --------| ---- + | %2B 空格 | %20 / | %2F ? | %3F % | %25 # | %23 & | %26 = | %3D查询某一类别的顶点或边(
query by label)时提示超时由于属于某一label的数据量可能比较多,请加上limit限制。
通过
RESTful API操作图是可以的,但是发送Gremlin语句就报错:Request Failed(500)可能是
GremlinServer的配置有误,检查gremlin-server.yaml的host、port是否与rest-server.properties的gremlinserver.url匹配,如不匹配则修改,然后重启服务。使用
Loader导数据出现Socket Timeout异常,然后导致Loader中断持续地导入数据会使
Server的压力过大,然后导致有些请求超时。可以通过调整Loader的参数来适当缓解Server压力(如:重试次数,重试间隔,错误容忍数等),降低该问题出现频率。如何删除全部的顶点和边,RESTful API中没有这样的接口,调用
gremlin的g.V().drop()会报错Vertices in transaction have reached capacity xxx目前确实没有好办法删除全部的数据,用户如果是自己部署的
Server和后端,可以直接清空数据库,重启Server。可以使用paging API或scan API先获取所有数据,再逐条删除。清空了数据库,并且执行了
init-store,但是添加schema时提示"xxx has existed"HugeGraphServer内是有缓存的,清空数据库的同时是需要重启Server的,否则残留的缓存会产生不一致。插入顶点或边的过程中报错:
Id max length is 128, but got xxx {yyy}或Big id max length is 32768, but got xxx为了保证查询性能,目前的后端存储对id列的长度做了限制,顶点id不能超过128字节,边id长度不能超过32768字节,索引id不能超过128字节。
是否支持嵌套属性,如果不支持,是否有什么替代方案
嵌套属性目前暂不支持。替代方案:可以把嵌套属性作为单独的顶点拿出来,然后用边连接起来。
一个
EdgeLabel是否可以连接多对VertexLabel,比如"投资"关系,可以是"个人"投资"企业",也可以是"企业"投资"企业"一个
EdgeLabel不支持连接多对VertexLabel,需要用户将EdgeLabel拆分得更细一点,如:“个人投资”,“企业投资”。通过
RestAPI发送请求时提示HTTP 415 Unsupported Media Type请求头中需要指定
Content-Type:application/json
其他问题可以在对应项目的 issue 区搜索,例如 Server-Issues / Loader Issues
7 - 报告安全问题
报告 Apache HugeGraph 的安全问题
遵循 ASF 的规范,HugeGraph 社区对解决修复项目中的安全问题保持非常积极和开放的态度。
我们强烈建议用户首先向我们的独立安全邮件列表报告此类问题,相关详细的流程规范请参考 ASF SEC 守则。
请注意,安全邮件组适用于报告未公开的安全漏洞并跟进漏洞处理的过程。常规的软件 Bug/Error 报告应该使用 Github Issue/Discussion
或是 HugeGraph-Dev 邮箱组。发送到安全邮件组但与安全问题无关的邮件将被忽略。
独立的安全邮件 (组) 地址为: security@hugegraph.apache.org
安全漏洞处理大体流程如下:
- 报告人私下向 Apache HugeGraph SEC 邮件组报告漏洞 (尽可能包括复现的版本/相关说明/复现方式/影响范围等)
- HugeGraph 项目安全团队与报告人私下合作/商讨漏洞解决方案 (初步确认后可申请
CVE编号予以登记) - 项目创建一个新版本的受漏洞影响的软件包,以提供修复程序
- 合适的时间可公开漏洞的大体问题 & 描述如何应用修复程序 (遵循 ASF 规范,公告中不应携带复现细节等敏感信息)
- 正式的 CVE 发布及相关流程同 ASF-SEC 页面
已发现的安全漏洞 (CVEs)
HugeGraph 主仓库 (Server/PD/Store)
- CVE-2024-27348: HugeGraph-Server - Command execution in gremlin
- CVE-2024-27349: HugeGraph-Server - Bypass whitelist in Auth mode
- CVE-2024-43441: HugeGraph-Server - Fixed JWT Token (Secret)
- CVE-2025-26866: HugeGraph-Server - RAFT and deserialization vulnerability
HugeGraph-Toolchain 仓库 (Hubble/Loader/Client/Tools/..)
- CVE-2024-27347: HugeGraph-Hubble - SSRF in Hubble connection page