HugeGraph Design Concepts
1. Property Graph
There are two common graph data representation models, namely the RDF (Resource Description Framework) model and the Property Graph (Property Graph) model. Both RDF and Property Graph are the most basic and well-known graph representation modes, and both can represent entity-relationship modeling of various graphs. RDF is a W3C standard, while Property Graph is an industry standard and is widely supported by graph database vendors. HugeGraph currently uses Property Graph.
The storage concept model corresponding to HugeGraph is also designed with reference to Property Graph. For specific examples, see the figure below: ( This figure is outdated for the old version design, please ignore it and update it later )
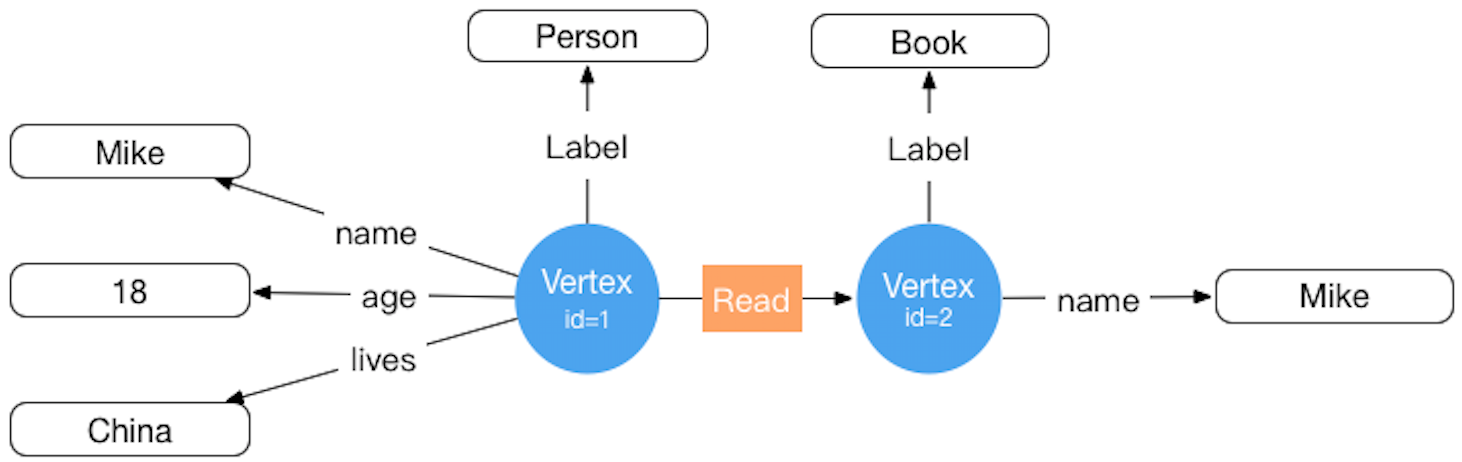
Inside HugeGraph, each vertex/edge is identified by a unique VertexId/EdgeId, and the attributes are stored inside the corresponding vertex/edge. The relationship/mapping between vertices is stored through edges.
When the vertex attribute value is stored by edge pointer, if you want to update a vertex-specific attribute value, you can directly write it by overwriting. The disadvantage is that the VertexId is redundantly stored; if you want to update the attribute of the relationship, you need to use the read-and-modify method , read all attributes first, modify some attributes, and then write to the storage system, the update efficiency is low. According to experience, there are more requirements for modifying vertex attributes, but less for edge attributes. For example, calculations such as PageRank and Graph Cluster require frequent modification of vertex attribute values.
2. Graph Partition Scheme
For distributed graph databases, there are two partition storage methods for graphs: Edge Cut and Vertex Cut, as shown in the following figure. When using the Edge Cut method to store graphs, any vertex will only appear on one machine, while edges may be distributed on different machines. This storage method may lead to multiple storage of edges. When using the Vertex Cut method to store graphs, any edge will only appear on one machine, and each same point may be distributed to different machines. This storage method may result in multiple storage of vertices.
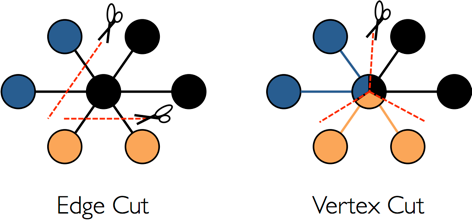
The EdgeCut partition scheme can support high-performance insert and update operations, while the VertexCut partition scheme is more suitable for static graph query analysis, so EdgeCut is suitable for OLTP graph query, and VertexCut is more suitable for OLAP graph query. HugeGraph currently adopts the partition scheme of EdgeCut.
3. VertexId Strategy
Vertex of HugeGraph supports three ID strategies. Different VertexLabels in the same graph database can use different Id strategies. Currently, the Id strategies supported by HugeGraph are:
- Automatic generation (AUTOMATIC): Use the Snowflake algorithm to automatically generate a globally unique Id, Long type;
- Primary Key (PRIMARY_KEY): Generate Id through VertexLabel+PrimaryKeyValues, String type;
- Custom (CUSTOMIZE_STRING|CUSTOMIZE_NUMBER): User-defined Id, which is divided into two types: String and Long, and you need to ensure the uniqueness of the Id yourself;
The default Id policy is AUTOMATIC, if the user calls the primaryKeys() method and sets the correct PrimaryKeys, the PRIMARY_KEY policy is automatically enabled. After enabling the PRIMARY_KEY strategy, HugeGraph can implement data deduplication based on PrimaryKeys.
- AUTOMATIC ID Policy
schema.vertexLabel("person")
.useAutomaticId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- PRIMARY_KEY ID policy
schema.vertexLabel("person")
.usePrimaryKeyId()
.properties("name", "age", "city")
.primaryKeys("name", "age")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- CUSTOMIZE_STRING ID Policy
schema.vertexLabel("person")
.useCustomizeStringId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, "123456", "name", "marko","age", 18, "city", "Beijing");
- CUSTOMIZE_NUMBER ID Policy
schema.vertexLabel("person")
.useCustomizeNumberId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, 123456, "name", "marko","age", 18, "city", "Beijing");
If users need Vertex deduplication, there are three options:
- Adopt PRIMARY_KEY strategy, automatic overwriting, suitable for batch insertion of large amount of data, users cannot know whether overwriting has occurred
- Adopt AUTOMATIC strategy, read-and-modify, suitable for small data insertion, users can clearly know whether overwriting occurs
- Using the CUSTOMIZE_STRING or CUSTOMIZE_NUMBER strategy, the user guarantees the uniqueness
4. EdgeId policy
The EdgeId of HugeGraph is composed of srcVertexId + edgeLabel + sortKey + tgtVertexId. Among them sortKey is an important concept of HugeGraph.
There are two reasons for adding Edge sortKeyas the unique ID of Edge:
- If there are multiple edges of the same Label between two vertices, they can be sortKeydistinguished by
- For SuperNode nodes, it can be sortKeysorted and truncated by.
Since EdgeId is composed of srcVertexId + edgeLabel + sortKey + tgtVertexId, HugeGraph will automatically overwrite when the same Edge is inserted
multiple times to achieve deduplication. It should be noted that the properties of Edge will also be overwritten in the batch insert mode.
In addition, because HugeGraph’s EdgeId adopts an automatic deduplication strategy, HugeGraph considers that there is only one edge in the case of self-loop (a vertex has an edge pointing to itself). The graph has two edges.
The edges of HugeGraph only support directed edges, and undirected edges can be realized by creating two edges, Out and In.
5. HugeGraph transaction overview
TinkerPop transaction overview
A TinkerPop transaction refers to a unit of work that performs operations on the database. A set of operations within a transaction either succeeds or all fail. For a detailed introduction, please refer to the official documentation of TinkerPop: http://tinkerpop.apache.org/docs/current/reference/#transactions:http://tinkerpop.apache.org/docs/current/reference/#transactions
TinkerPop transaction overview
- open open transaction
- commit commit transaction
- rollback rollback transaction
- close closes the transaction
TinkerPop transaction specification
- The transaction must be explicitly committed before it can take effect (the modification operation can only be seen by the query in this transaction if it is not committed)
- A transaction must be opened before it can be committed or rolled back
- If the transaction setting is automatically turned on, there is no need to explicitly turn it on (the default method), if it is set to be turned on manually, it must be turned on explicitly
- When the transaction is closed, you can set three modes: automatic commit, automatic rollback (default mode), manual (explicit shutdown is prohibited), etc.
- The transaction must be closed after committing or rolling back
- The transaction must be open after the query
- Transactions (non-threaded tx) must be thread-isolated, and multi-threaded operations on the same transaction do not affect each other
For more transaction specification use cases, see: Transaction Test
HugeGraph transaction implementation
- All operations in a transaction either succeed or fail
- A transaction can only read what has been committed by another transaction (Read committed)
- All uncommitted operations can be queried in this transaction, including:
- Adding a vertex can query the vertex
- Delete a vertex to filter out the vertex
- Deleting a vertex can filter out the related edges of the vertex
- Adding an edge can query the edge
- Delete edge can filter out the edge
- Adding/modifying (vertex, edge) attributes can take effect when querying
- Delete (vertex, edge) attributes can take effect at query time
- All uncommitted operations become invalid after the transaction is rolled back, including:
- Adding and deleting vertices and edges
- Addition/modification, deletion of attributes
Example: One transaction cannot read another transaction’s uncommitted content
static void testUncommittedTx(final HugeGraph graph) throws InterruptedException {
final CountDownLatch latchUncommit = new CountDownLatch(1);
final CountDownLatch latchRollback = new CountDownLatch(1);
Thread thread = new Thread(() -> {
// this is a new transaction in the new thread
graph.tx().open();
System.out.println("current transaction operations");
Vertex james = graph.addVertex(T.label, "author",
"id", 1, "name", "James Gosling",
"age", 62, "lived", "Canadian");
Vertex java = graph.addVertex(T.label, "language", "name", "java",
"versions", Arrays.asList(6, 7, 8));
james.addEdge("created", java);
// we can query the uncommitted records in the current transaction
System.out.println("current transaction assert");
assert graph.vertices().hasNext() == true;
assert graph.edges().hasNext() == true;
latchUncommit.countDown();
try {
latchRollback.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("current transaction rollback");
graph.tx().rollback();
});
thread.start();
// query none result in other transaction when not commit()
latchUncommit.await();
System.out.println("other transaction assert for uncommitted");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
latchRollback.countDown();
thread.join();
// query none result in other transaction after rollback()
System.out.println("other transaction assert for rollback");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
}
Principle of transaction realization
- The server internally realizes isolation by binding transactions to threads (ThreadLocal)
- The uncommitted content of this transaction overwrites the old data in chronological order for this transaction to query the latest version of data
- The bottom layer relies on the back-end database to ensure transaction atomicity (for example, the batch interface of Cassandra/RocksDB guarantees atomicity)
Notice
The RESTful API does not expose the transaction interface for the time being
TinkerPop API allows open transactions, which are automatically closed when the request is completed (Gremlin Server forces close)