This is the multi-page printable view of this section. Click here to print.
QUERY LANGUAGE
1 - HugeGraph Gremlin
Overview
HugeGraph supports Gremlin, a graph traversal query language of Apache TinkerPop3. While SQL is a query language for relational databases, Gremlin is a general-purpose query language for graph databases. Gremlin can be used to create entities (Vertex and Edge) of a graph, modify the properties of entities, delete entities, as well as perform graph queries.
Gremlin can be used to create entities (Vertex and Edge) of a graph, modify the properties of entities, and delete entities. More importantly, it can be used to perform graph querying and analysis operations.
TinkerPop Features
HugeGraph implements the TinkerPop framework, but not all TinkerPop features are implemented.
The table below lists the support status of various TinkerPop features in HugeGraph:
Graph Features
| Name | Description | Support |
|---|---|---|
| Computer | Determines if the {@code Graph} implementation supports {@link GraphComputer} based processing | false |
| Transactions | Determines if the {@code Graph} implementations supports transactions. | true |
| Persistence | Determines if the {@code Graph} implementation supports persisting it’s contents natively to disk.This feature does not refer to every graph’s ability to write to disk via the Gremlin IO packages(.e.g. GraphML), unless the graph natively persists to disk via those options somehow. For example,TinkerGraph does not support this feature as it is a pure in-sideEffects graph. | true |
| ThreadedTransactions | Determines if the {@code Graph} implementation supports threaded transactions which allow a transaction be executed across multiple threads via {@link Transaction#createThreadedTx()}. | false |
| ConcurrentAccess | Determines if the {@code Graph} implementation supports more than one connection to the same instance at the same time. For example, Neo4j embedded does not support this feature because concurrent access to the same database files by multiple instances is not possible. However, Neo4j HA could support this feature as each new {@code Graph} instance coordinates with the Neo4j cluster allowing multiple instances to operate on the same database. | false |
Vertex Features
| Name | Description | Support |
|---|---|---|
| UserSuppliedIds | Determines if an {@link Element} can have a user defined identifier. Implementation that do not support this feature will be expected to auto-generate unique identifiers. In other words, if the {@link Graph} allows {@code graph.addVertex(id,x)} to work and thus set the identifier of the newly added {@link Vertex} to the value of {@code x} then this feature should return true. In this case, {@code x} is assumed to be an identifier data type that the {@link Graph} will accept. | false |
| NumericIds | Determines if an {@link Element} has numeric identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a numeric value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| StringIds | Determines if an {@link Element} has string identifiers as their internal representation. In other words, if the value returned from {@link Element#id()} is a string value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| UuidIds | Determines if an {@link Element} has UUID identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a {@link UUID} value then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| CustomIds | Determines if an {@link Element} has a specific custom object as their internal representation.In other words, if the value returned from {@link Element#id()} is a type defined by the graph implementations, such as OrientDB’s {@code Rid}, then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| AnyIds | Determines if an {@link Element} any Java object is a suitable identifier. TinkerGraph is a good example of a {@link Graph} that can support this feature, as it can use any {@link Object} as a value for the identifier. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. This setting should only return {@code true} if {@link #supportsUserSuppliedIds()} is {@code true}. | false |
| AddProperty | Determines if an {@link Element} allows properties to be added. This feature is set independently from supporting “data types” and refers to support of calls to {@link Element#property(String, Object)}. | true |
| RemoveProperty | Determines if an {@link Element} allows properties to be removed. | true |
| AddVertices | Determines if a {@link Vertex} can be added to the {@code Graph}. | true |
| MultiProperties | Determines if a {@link Vertex} can support multiple properties with the same key. | false |
| DuplicateMultiProperties | Determines if a {@link Vertex} can support non-unique values on the same key. For this value to be {@code true}, then {@link #supportsMetaProperties()} must also return true. By default this method, just returns what {@link #supportsMultiProperties()} returns. | false |
| MetaProperties | Determines if a {@link Vertex} can support properties on vertex properties. It is assumed that a graph will support all the same data types for meta-properties that are supported for regular properties. | false |
| RemoveVertices | Determines if a {@link Vertex} can be removed from the {@code Graph}. | true |
Edge Features
| Name | Description | Support |
|---|---|---|
| UserSuppliedIds | Determines if an {@link Element} can have a user defined identifier. Implementation that do not support this feature will be expected to auto-generate unique identifiers. In other words, if the {@link Graph} allows {@code graph.addVertex(id,x)} to work and thus set the identifier of the newly added {@link Vertex} to the value of {@code x} then this feature should return true. In this case, {@code x} is assumed to be an identifier data type that the {@link Graph} will accept. | false |
| NumericIds | Determines if an {@link Element} has numeric identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a numeric value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| StringIds | Determines if an {@link Element} has string identifiers as their internal representation. In other words, if the value returned from {@link Element#id()} is a string value then this method should be return {@code true}. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| UuidIds | Determines if an {@link Element} has UUID identifiers as their internal representation. In other words,if the value returned from {@link Element#id()} is a {@link UUID} value then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| CustomIds | Determines if an {@link Element} has a specific custom object as their internal representation.In other words, if the value returned from {@link Element#id()} is a type defined by the graph implementations, such as OrientDB’s {@code Rid}, then this method should be return {@code true}.Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. | false |
| AnyIds | Determines if an {@link Element} any Java object is a suitable identifier. TinkerGraph is a good example of a {@link Graph} that can support this feature, as it can use any {@link Object} as a value for the identifier. Note that this feature is most generally used for determining the appropriate tests to execute in the Gremlin Test Suite. This setting should only return {@code true} if {@link #supportsUserSuppliedIds()} is {@code true}. | false |
| AddProperty | Determines if an {@link Element} allows properties to be added. This feature is set independently from supporting “data types” and refers to support of calls to {@link Element#property(String, Object)}. | true |
| RemoveProperty | Determines if an {@link Element} allows properties to be removed. | true |
| AddEdges | Determines if an {@link Edge} can be added to a {@code Vertex}. | true |
| RemoveEdges | Determines if an {@link Edge} can be removed from a {@code Vertex}. | true |
Data Type Features
| Name | Description | Support |
|---|---|---|
| BooleanValues | true | |
| ByteValues | true | |
| DoubleValues | true | |
| FloatValues | true | |
| IntegerValues | true | |
| LongValues | true | |
| MapValues | Supports setting of a {@code Map} value. The assumption is that the {@code Map} can contain arbitrary serializable values that may or may not be defined as a feature itself | false |
| MixedListValues | Supports setting of a {@code List} value. The assumption is that the {@code List} can contain arbitrary serializable values that may or may not be defined as a feature itself. As this{@code List} is “mixed” it does not need to contain objects of the same type. | false |
| BooleanArrayValues | false | |
| ByteArrayValues | true | |
| DoubleArrayValues | false | |
| FloatArrayValues | false | |
| IntegerArrayValues | false | |
| LongArrayValues | false | |
| SerializableValues | false | |
| StringArrayValues | false | |
| StringValues | true | |
| UniformListValues | Supports setting of a {@code List} value. The assumption is that the {@code List} can contain arbitrary serializable values that may or may not be defined as a feature itself. As this{@code List} is “uniform” it must contain objects of the same type. | false |
Gremlin Steps
HugeGraph supports all steps of Gremlin. For complete reference information about Gremlin, please refer to the Gremlin official website.
| Step | Description | Documentation |
|---|---|---|
| addE | Add an edge between two vertices. | addE step |
| addV | add vertices to graph. | addV step |
| and | Make sure all traversals return values. | and step |
| as | Step modulator for assigning variables to the step’s output. | as step |
| by | Step Modulators used in conjunction with group and order. | by step |
| coalesce | Returns the first traversal that returns a result. | coalesce step |
| constant | Returns a constant value. Used in conjunction with coalesce. | constant step |
| count | Returns a count from the traversal. | count step |
| dedup | Returns values with duplicates removed. | dedup step |
| drop | Discards a value (vertex/edge). | drop step |
| fold | Acts as a barrier for computing aggregated values from results. | fold step |
| group | Groups values based on specified labels. | group step |
| has | Used to filter properties, vertices, and edges. Supports hasLabel, hasId, hasNot, and has variants. | has step |
| inject | Injects values into the stream. | inject step |
| is | Used to filter by a Boolean expression. | is step |
| limit | Used to limit the number of items in a traversal. | limit step |
| local | Locally wraps a part of a traversal, similar to a subquery. | local step |
| not | Used to generate the negation result of a filter. | not step |
| optional | Returns the result of a specified traversal if it generates any results, otherwise returns the calling element. | optional step |
| or | Ensures that at least one traversal returns a value. | or step |
| order | Returns results in the specified order. | order step |
| path | Returns the full path of the traversal. | path step |
| project | Projects properties as a map. | project step |
| properties | Returns properties with specified labels. | properties step |
| range | Filters based on a specified range of values. | range step |
| repeat | Repeats a step a specified number of times. Used for looping. | repeat step |
| sample | Used to sample results returned by the traversal. | sample step |
| select | Used to project the results returned by the traversal. | select step |
| store | This step is used fo.r non-blocking aggregation of results returned by traversal | store step |
| tree | Aggregate the paths in vertices into a tree. | tree step |
| unfold | Unfolds an iterator as a step. | unfold step |
| union | Merge the results returned by multiple traversals. | union step |
| V | These are the steps required for traversing between vertices and edges: V, E, out, in, both, outE, inE, bothE, outV, inV, bothV, and otherV. | order step |
| where | Used to filter the results returned by a traversal. Supports eq, neq, lt, lte, gt, gte, and between operators. | where step |
2 - HugeGraph Examples
1 Overview
This example uses the TitanDB Getting Started guide as a template to demonstrate how to use HugeGraph. By comparing HugeGraph and TitanDB, you can understand the differences between them.
1.1 Similarities and Differences between HugeGraph and TitanDB
Both HugeGraph and TitanDB are graph databases based on the Apache TinkerPop3 framework. They both support the Gremlin graph query language and share many similarities in terms of usage and interfaces. However, HugeGraph is a completely new design and development, characterized by its clear code structure, richer features, and more user-friendly interfaces.
Compared to TitanDB, HugeGraph’s main features are as follows:
- HugeGraph currently offers a comprehensive suite of tools, including HugeGraph-API, HugeGraph-Client, HugeGraph-Loader, HugeGraph-Studio, and HugeGraph-Spark. These components facilitate system integration, data loading, visual graph querying, Spark connectivity, and other functionalities.
- HugeGraph incorporates the concepts of Server and Client, allowing third-party systems to connect via multiple methods such as JAR references, clients, and APIs. In contrast, TitanDB only supports connections via JAR references.
- HugeGraph requires explicit schema definition, and all insertions and queries must pass strict schema validation. Implicit schema creation is not supported at the moment.
- HugeGraph makes full use of the characteristics of the underlying storage system to achieve efficient data access, whereas TitanDB ignores the differences of the backend with a unified Kv structure.
- HugeGraph’s update operations can be performed on-demand (e.g., updating a specific attribute), offering better performance. TitanDB uses a read-and-update approach for updates.
- Both VertexId and EdgeId in HugeGraph support concatenation, allowing for automatic deduplication and better query performance. In TitanDB, all IDs are auto-generated and require indexing for queries.
1.2 Character Relationship Graph
This example uses the Property Graph Model to describe the relationships between characters in Greek mythology, also known as the character relationship graph. The specific relationships are shown in the diagram below.
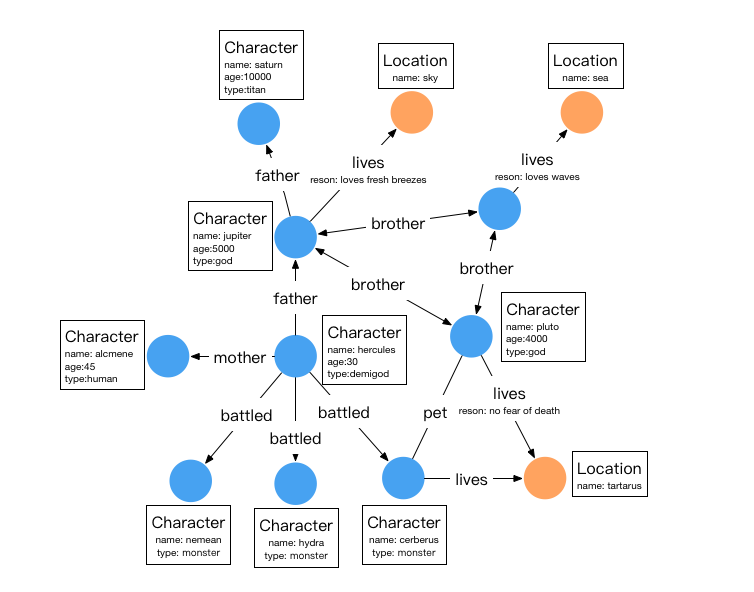
In the diagram, circular nodes represent entities (Vertices), arrows represent relationships (Edges), and the content in the boxes represents attributes.
There are two types of vertices in this graph: characters and locations, as shown in the table below:
| Name | Type | Attributes |
|---|---|---|
| character | vertex | name,age,type |
| location | vertex | name |
There are six types of relationships: father, mother, brother, battled, lives, and pet. The details of these relationships are as follows:
| Name | Type | Source Vertex Label | Target Vertex Label | Attributes |
|---|---|---|---|---|
| father | edge | character | character | - |
| mother | edge | character | character | - |
| brother | edge | character | character | - |
| pet | edge | character | character | - |
| lives | edge | character | location | reason |
In HugeGraph, each edge label can only act on one pair of source and target vertex labels. In other words, if a relationship called “father” is defined in the graph to connect character to character, then “father” cannot be used to connect to other vertex labels.
Therefore, in this example, the original TitanDB’s monster, god, human, and demigod are all represented using the same vertex label: character in HugeGraph, with an additional type attribute to indicate the type of character. The edge labels remain consistent with the original TitanDB. Of course, to satisfy the edge label constraints, adjustments can be made to the name of the edge label.
2 Graph Schema and Data Ingest Examples
HugeGraph requires explicit schema creation, which involves creating PropertyKeys, VertexLabels, and EdgeLabels in sequence. If indexing is needed, IndexLabels must also be created.
2.1 Graph Schema
schema = hugegraph.schema()
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("age").asInt().ifNotExist().create()
schema.propertyKey("time").asInt().ifNotExist().create()
schema.propertyKey("reason").asText().ifNotExist().create()
schema.propertyKey("type").asText().ifNotExist().create()
schema.vertexLabel("character").properties("name", "age", "type").primaryKeys("name").nullableKeys("age").ifNotExist().create()
schema.vertexLabel("location").properties("name").primaryKeys("name").ifNotExist().create()
schema.edgeLabel("father").link("character", "character").ifNotExist().create()
schema.edgeLabel("mother").link("character", "character").ifNotExist().create()
schema.edgeLabel("battled").link("character", "character").properties("time").ifNotExist().create()
schema.edgeLabel("lives").link("character", "location").properties("reason").nullableKeys("reason").ifNotExist().create()
schema.edgeLabel("pet").link("character", "character").ifNotExist().create()
schema.edgeLabel("brother").link("character", "character").ifNotExist().create()
2.2 Graph Data
// add vertices
Vertex saturn = graph.addVertex(T.label, "character", "name", "saturn", "age", 10000, "type", "titan")
Vertex sky = graph.addVertex(T.label, "location", "name", "sky")
Vertex sea = graph.addVertex(T.label, "location", "name", "sea")
Vertex jupiter = graph.addVertex(T.label, "character", "name", "jupiter", "age", 5000, "type", "god")
Vertex neptune = graph.addVertex(T.label, "character", "name", "neptune", "age", 4500, "type", "god")
Vertex hercules = graph.addVertex(T.label, "character", "name", "hercules", "age", 30, "type", "demigod")
Vertex alcmene = graph.addVertex(T.label, "character", "name", "alcmene", "age", 45, "type", "human")
Vertex pluto = graph.addVertex(T.label, "character", "name", "pluto", "age", 4000, "type", "god")
Vertex nemean = graph.addVertex(T.label, "character", "name", "nemean", "type", "monster")
Vertex hydra = graph.addVertex(T.label, "character", "name", "hydra", "type", "monster")
Vertex cerberus = graph.addVertex(T.label, "character", "name", "cerberus", "type", "monster")
Vertex tartarus = graph.addVertex(T.label, "location", "name", "tartarus")
// add edges
jupiter.addEdge("father", saturn)
jupiter.addEdge("lives", sky, "reason", "loves fresh breezes")
jupiter.addEdge("brother", neptune)
jupiter.addEdge("brother", pluto)
neptune.addEdge("lives", sea, "reason", "loves waves")
neptune.addEdge("brother", jupiter)
neptune.addEdge("brother", pluto)
hercules.addEdge("father", jupiter)
hercules.addEdge("mother", alcmene)
hercules.addEdge("battled", nemean, "time", 1)
hercules.addEdge("battled", hydra, "time", 2)
hercules.addEdge("battled", cerberus, "time", 12)
pluto.addEdge("brother", jupiter)
pluto.addEdge("brother", neptune)
pluto.addEdge("lives", tartarus, "reason", "no fear of death")
pluto.addEdge("pet", cerberus)
cerberus.addEdge("lives", tartarus)
2.3 Indices
HugeGraph by default automatically generates IDs. However, if a user specifies the primaryKeys field list for a VertexLabel through primaryKeys, the ID strategy for that VertexLabel will automatically switch to the primaryKeys strategy. Once the primaryKeys strategy is enabled, HugeGraph generates VertexId by concatenating vertexLabel+primaryKeys, which allows for automatic deduplication. Additionally, there is no need to create extra indexes to use the properties in primaryKeys for fast querying. For example, both “character” and “location” have the primaryKeys("name") attribute, so without creating additional indexes, vertices can be queried using g.V().hasLabel('character') .has('name','hercules').
3 Graph Traversal Examples
3.1 Traversal Query
1. Find the grandfather of hercules
g.V().hasLabel('character').has('name','hercules').out('father').out('father')
It can also be done using the repeat method:
g.V().hasLabel('character').has('name','hercules').repeat(__.out('father')).times(2)
2. Find the name of Hercules’s father
g.V().hasLabel('character').has('name','hercules').out('father').value('name')
3. Find the characters with age > 100
g.V().hasLabel('character').has('age',gt(100))
4. Find who are pluto’s cohabitants
g.V().hasLabel('character').has('name','pluto').out('lives').in('lives').values('name')
5. Find pluto can’t be his own cohabitant
pluto = g.V().hasLabel('character').has('name', 'pluto')
g.V(pluto).out('lives').in('lives').where(is(neq(pluto)).values('name')
// use 'as'
g.V().hasLabel('character').has('name', 'pluto').as('x').out('lives').in('lives').where(neq('x')).values('name')
6. Pluto’s Brothers
pluto = g.V().hasLabel('character').has('name', 'pluto').next()
// where do pluto's brothers live?
g.V(pluto).out('brother').out('lives').values('name')
// which brother lives in which place?
g.V(pluto).out('brother').as('god').out('lives').as('place').select('god','place')
// what is the name of the brother and the name of the place?
g.V(pluto).out('brother').as('god').out('lives').as('place').select('god','place').by('name')
It is recommended to use HugeGraph-Hubble to execute the above code visually. Additionally, the code can be executed through various other methods such as HugeGraph-Client, HugeGraph-Api, GremlinConsole, and GremlinDriver.
3.2 Summary
HugeGraph currently supports Gremlin syntax, and users can implement various query requirements through Gremlin / REST-API.