This is the multi-page printable view of this section. Click here to print.
GUIDES
1 - HugeGraph Architecture Overview
1 Overview
As a full-stack graph system covering Graph Database, Graph Computing, and Graph AI, HugeGraph is centered around a high-performance graph engine (HugeGraph Server) and supports both OLTP and OLAP graph computation types. For the OLTP layer, it implements the Apache TinkerPop3 framework and supports the Gremlin and Cypher query languages. It comes with a complete application toolchain and provides a pluggable backend storage driver framework.
Below is the overall architecture diagram of HugeGraph:
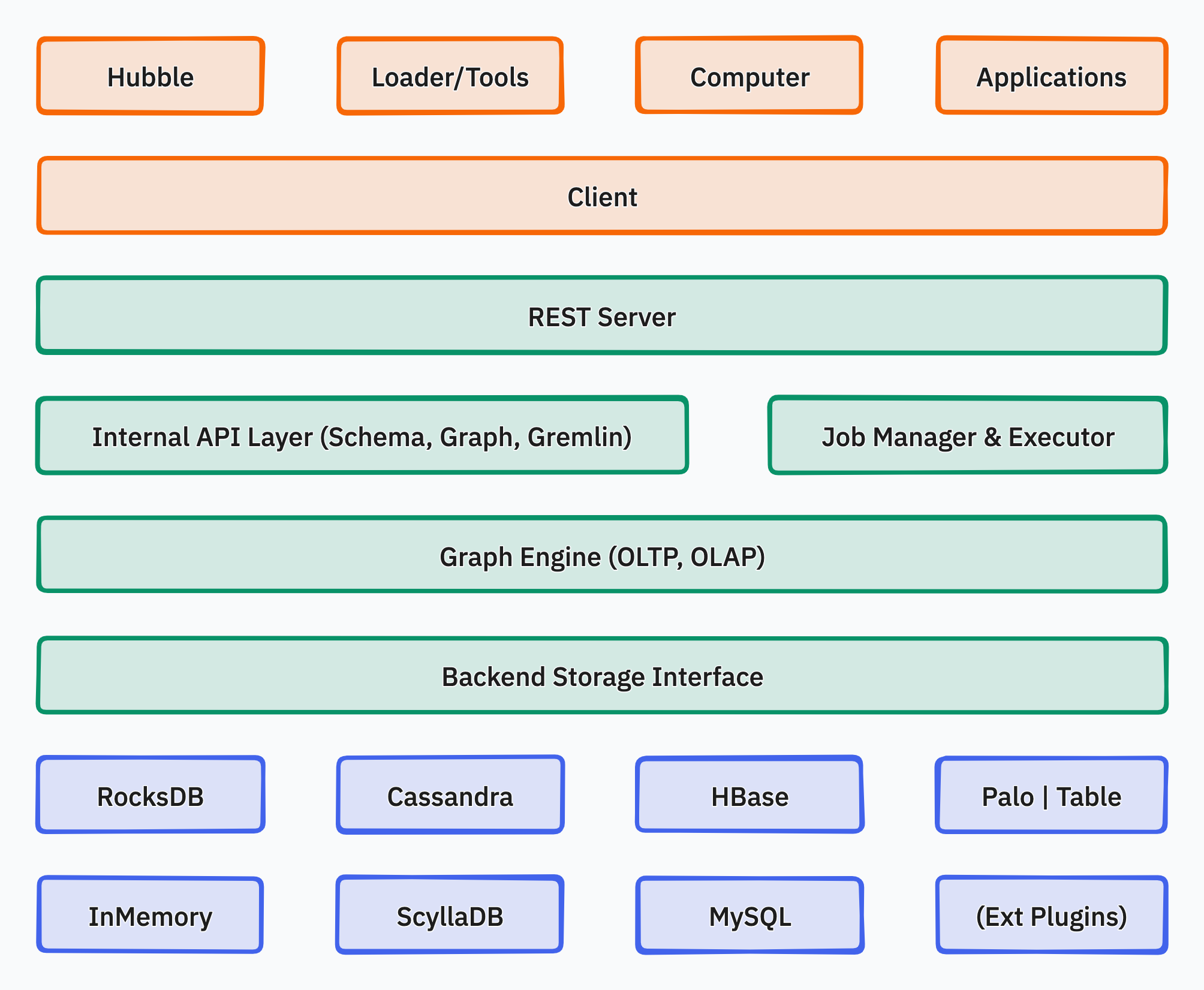
HugeGraph consists of three layers of functionality: the application layer, the graph engine layer, and the storage layer.
- Application Layer:
- Hubble: A one-stop visual analysis platform that covers the entire process from data modeling to rapid data import, online and offline analysis, and unified graph management, realizing wizard-style operations for the entire graph application process.
- Loader: A data import component that can transform data from multiple data sources into graph vertices and edges and batch import them into the graph database.
- Tools: Command-line tools for deploying, managing, and backing up/restoring data in HugeGraph.
- Computer: A distributed graph processing system (OLAP), which is an implementation of Pregel and can run on Kubernetes.
- Client: A HugeGraph client written in Java. Users can use the Client to write Java code to operate HugeGraph. Python, Go, C++ and other language support will be provided in the future as needed.
- Graph Engine Layer:
- REST Server: Provides a RESTful API for querying graph/schema information, supports the Gremlin and Cypher query languages, and offers APIs for service monitoring and operations.
- Graph Engine: Supports both OLTP and OLAP graph computation types, with OLTP implementing the Apache TinkerPop3 framework.
- Backend Interface: Implements the storage of graph data to the backend.
- Storage Layer:
- Storage Backend: Supports multiple built-in storage backends (RocksDB/MySQL/HBase/…) and allows users to extend custom backends without modifying the existing source code.
2 - HugeGraph Design Concepts
1. Property Graph
There are two common graph data representation models, namely the RDF (Resource Description Framework) model and the Property Graph (Property Graph) model. Both RDF and Property Graph are the most basic and well-known graph representation modes, and both can represent entity-relationship modeling of various graphs. RDF is a W3C standard, while Property Graph is an industry standard and is widely supported by graph database vendors. HugeGraph currently uses Property Graph.
The storage concept model corresponding to HugeGraph is also designed with reference to Property Graph. For specific examples, see the figure below: ( This figure is outdated for the old version design, please ignore it and update it later )
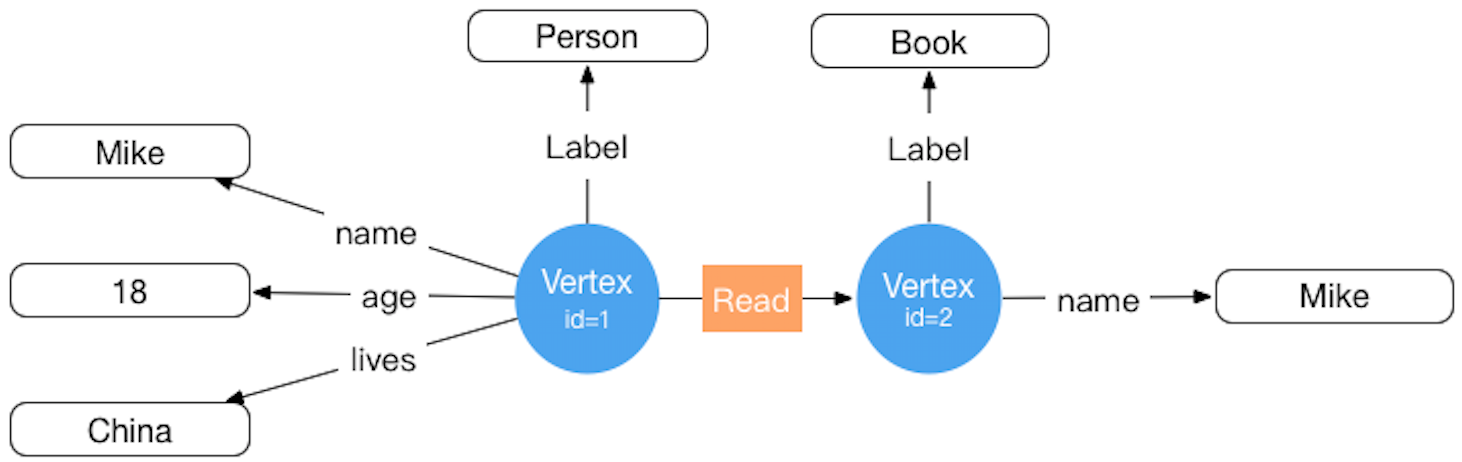
Inside HugeGraph, each vertex/edge is identified by a unique VertexId/EdgeId, and the attributes are stored inside the corresponding vertex/edge. The relationship/mapping between vertices is stored through edges.
When the vertex attribute value is stored by edge pointer, if you want to update a vertex-specific attribute value, you can directly write it by overwriting. The disadvantage is that the VertexId is redundantly stored; if you want to update the attribute of the relationship, you need to use the read-and-modify method , read all attributes first, modify some attributes, and then write to the storage system, the update efficiency is low. According to experience, there are more requirements for modifying vertex attributes, but less for edge attributes. For example, calculations such as PageRank and Graph Cluster require frequent modification of vertex attribute values.
2. Graph Partition Scheme
For distributed graph databases, there are two partition storage methods for graphs: Edge Cut and Vertex Cut, as shown in the following figure. When using the Edge Cut method to store graphs, any vertex will only appear on one machine, while edges may be distributed on different machines. This storage method may lead to multiple storage of edges. When using the Vertex Cut method to store graphs, any edge will only appear on one machine, and each same point may be distributed to different machines. This storage method may result in multiple storage of vertices.
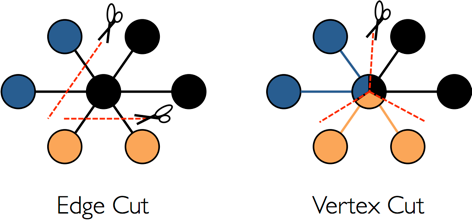
The EdgeCut partition scheme can support high-performance insert and update operations, while the VertexCut partition scheme is more suitable for static graph query analysis, so EdgeCut is suitable for OLTP graph query, and VertexCut is more suitable for OLAP graph query. HugeGraph currently adopts the partition scheme of EdgeCut.
3. VertexId Strategy
Vertex of HugeGraph supports three ID strategies. Different VertexLabels in the same graph database can use different Id strategies. Currently, the Id strategies supported by HugeGraph are:
- Automatic generation (AUTOMATIC): Use the Snowflake algorithm to automatically generate a globally unique Id, Long type;
- Primary Key (PRIMARY_KEY): Generate Id through VertexLabel+PrimaryKeyValues, String type;
- Custom (CUSTOMIZE_STRING|CUSTOMIZE_NUMBER): User-defined Id, which is divided into two types: String and Long, and you need to ensure the uniqueness of the Id yourself;
The default Id policy is AUTOMATIC, if the user calls the primaryKeys() method and sets the correct PrimaryKeys, the PRIMARY_KEY policy is automatically enabled. After enabling the PRIMARY_KEY strategy, HugeGraph can implement data deduplication based on PrimaryKeys.
- AUTOMATIC ID Policy
schema.vertexLabel("person")
.useAutomaticId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- PRIMARY_KEY ID policy
schema.vertexLabel("person")
.usePrimaryKeyId()
.properties("name", "age", "city")
.primaryKeys("name", "age")
.create();
graph.addVertex(T.label, "person","name", "marko", "age", 18, "city", "Beijing");
- CUSTOMIZE_STRING ID Policy
schema.vertexLabel("person")
.useCustomizeStringId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, "123456", "name", "marko","age", 18, "city", "Beijing");
- CUSTOMIZE_NUMBER ID Policy
schema.vertexLabel("person")
.useCustomizeNumberId()
.properties("name", "age", "city")
.create();
graph.addVertex(T.label, "person", T.id, 123456, "name", "marko","age", 18, "city", "Beijing");
If users need Vertex deduplication, there are three options:
- Adopt PRIMARY_KEY strategy, automatic overwriting, suitable for batch insertion of large amount of data, users cannot know whether overwriting has occurred
- Adopt AUTOMATIC strategy, read-and-modify, suitable for small data insertion, users can clearly know whether overwriting occurs
- Using the CUSTOMIZE_STRING or CUSTOMIZE_NUMBER strategy, the user guarantees the uniqueness
4. EdgeId policy
The EdgeId of HugeGraph is composed of srcVertexId + edgeLabel + sortKey + tgtVertexId. Among them sortKey is an important concept of HugeGraph.
There are two reasons for adding Edge sortKeyas the unique ID of Edge:
- If there are multiple edges of the same Label between two vertices, they can be sortKeydistinguished by
- For SuperNode nodes, it can be sortKeysorted and truncated by.
Since EdgeId is composed of srcVertexId + edgeLabel + sortKey + tgtVertexId, HugeGraph will automatically overwrite when the same Edge is inserted
multiple times to achieve deduplication. It should be noted that the properties of Edge will also be overwritten in the batch insert mode.
In addition, because HugeGraph’s EdgeId adopts an automatic deduplication strategy, HugeGraph considers that there is only one edge in the case of self-loop (a vertex has an edge pointing to itself). The graph has two edges.
The edges of HugeGraph only support directed edges, and undirected edges can be realized by creating two edges, Out and In.
5. HugeGraph transaction overview
TinkerPop transaction overview
A TinkerPop transaction refers to a unit of work that performs operations on the database. A set of operations within a transaction either succeeds or all fail. For a detailed introduction, please refer to the official documentation of TinkerPop: http://tinkerpop.apache.org/docs/current/reference/#transactions:http://tinkerpop.apache.org/docs/current/reference/#transactions
TinkerPop transaction overview
- open open transaction
- commit commit transaction
- rollback rollback transaction
- close closes the transaction
TinkerPop transaction specification
- The transaction must be explicitly committed before it can take effect (the modification operation can only be seen by the query in this transaction if it is not committed)
- A transaction must be opened before it can be committed or rolled back
- If the transaction setting is automatically turned on, there is no need to explicitly turn it on (the default method), if it is set to be turned on manually, it must be turned on explicitly
- When the transaction is closed, you can set three modes: automatic commit, automatic rollback (default mode), manual (explicit shutdown is prohibited), etc.
- The transaction must be closed after committing or rolling back
- The transaction must be open after the query
- Transactions (non-threaded tx) must be thread-isolated, and multi-threaded operations on the same transaction do not affect each other
For more transaction specification use cases, see: Transaction Test
HugeGraph transaction implementation
- All operations in a transaction either succeed or fail
- A transaction can only read what has been committed by another transaction (Read committed)
- All uncommitted operations can be queried in this transaction, including:
- Adding a vertex can query the vertex
- Delete a vertex to filter out the vertex
- Deleting a vertex can filter out the related edges of the vertex
- Adding an edge can query the edge
- Delete edge can filter out the edge
- Adding/modifying (vertex, edge) attributes can take effect when querying
- Delete (vertex, edge) attributes can take effect at query time
- All uncommitted operations become invalid after the transaction is rolled back, including:
- Adding and deleting vertices and edges
- Addition/modification, deletion of attributes
Example: One transaction cannot read another transaction’s uncommitted content
static void testUncommittedTx(final HugeGraph graph) throws InterruptedException {
final CountDownLatch latchUncommit = new CountDownLatch(1);
final CountDownLatch latchRollback = new CountDownLatch(1);
Thread thread = new Thread(() -> {
// this is a new transaction in the new thread
graph.tx().open();
System.out.println("current transaction operations");
Vertex james = graph.addVertex(T.label, "author",
"id", 1, "name", "James Gosling",
"age", 62, "lived", "Canadian");
Vertex java = graph.addVertex(T.label, "language", "name", "java",
"versions", Arrays.asList(6, 7, 8));
james.addEdge("created", java);
// we can query the uncommitted records in the current transaction
System.out.println("current transaction assert");
assert graph.vertices().hasNext() == true;
assert graph.edges().hasNext() == true;
latchUncommit.countDown();
try {
latchRollback.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("current transaction rollback");
graph.tx().rollback();
});
thread.start();
// query none result in other transaction when not commit()
latchUncommit.await();
System.out.println("other transaction assert for uncommitted");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
latchRollback.countDown();
thread.join();
// query none result in other transaction after rollback()
System.out.println("other transaction assert for rollback");
assert !graph.vertices().hasNext();
assert !graph.edges().hasNext();
}
Principle of transaction realization
- The server internally realizes isolation by binding transactions to threads (ThreadLocal)
- The uncommitted content of this transaction overwrites the old data in chronological order for this transaction to query the latest version of data
- The bottom layer relies on the back-end database to ensure transaction atomicity (for example, the batch interface of Cassandra/RocksDB guarantees atomicity)
Notice
The RESTful API does not expose the transaction interface for the time being
TinkerPop API allows open transactions, which are automatically closed when the request is completed (Gremlin Server forces close)
3 - HugeGraph Plugin mechanism and plug-in extension process
Background
- HugeGraph is not only open source and open, but also simple and easy to use. General users can easily add plug-in extension functions without changing the source code.
- HugeGraph supports a variety of built-in storage backends, and also allows users to extend custom backends without changing the existing source code.
- HugeGraph supports full-text search. The full-text search function involves word segmentation in various languages. Currently, there are 8 built-in Chinese word breakers, and it also allows users to expand custom word breakers without changing the existing source code.
Scalable dimension
Currently, the plug-in method provides extensions in the following dimensions:
- backend storage
- serializer
- Custom configuration items
- tokenizer
Plug-in implementation mechanism
- HugeGraph provides a plug-in interface HugeGraphPlugin, which supports plug-in through the Java SPI mechanism
- HugeGraph provides four extension registration functions: registerOptions(), registerBackend(), registerSerializer(),registerAnalyzer()
- The plug-in implementer implements the corresponding Options, Backend, Serializer or Analyzer interface
- The plug-in implementer implements register()the method of the HugeGraphPlugin interface, registers the specific implementation class listed in the above point 3 in this method, and packs it into a jar package
- The plug-in user puts the jar package in the HugeGraph Server installation directory plugins, modifies the relevant configuration items to the plug-in custom value, and restarts to take effect
Plug-in implementation process example
1 Create a new maven project
1.1 Name the project name: hugegraph-plugin-demo
1.2 Add hugegraph-core Jar package dependencies
The details of maven pom.xml are as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.hugegraph</groupId>
<artifactId>hugegraph-plugin-demo</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>hugegraph-plugin-demo</name>
<dependencies>
<dependency>
<groupId>org.apache.hugegraph</groupId>
<artifactId>hugegraph-core</artifactId>
<version>${project.version}</version>
</dependency>
</dependencies>
</project>
2 Realize extended functions
2.1 Extending a custom backend
2.1.1 Implement the interface BackendStoreProvider
- Realizable interfaces:
org.apache.hugegraph.backend.store.BackendStoreProvider - Or inherit an abstract class:
org.apache.hugegraph.backend.store.AbstractBackendStoreProvider
Take the RocksDB backend RocksDBStoreProvider as an example:
public class RocksDBStoreProvider extends AbstractBackendStoreProvider {
protected String database() {
return this.graph().toLowerCase();
}
@Override
protected BackendStore newSchemaStore(String store) {
return new RocksDBSchemaStore(this, this.database(), store);
}
@Override
protected BackendStore newGraphStore(String store) {
return new RocksDBGraphStore(this, this.database(), store);
}
@Override
public String type() {
return "rocksdb";
}
@Override
public String version() {
return "1.0";
}
}
2.1.2 Implement interface BackendStore
The BackendStore interface is defined as follows:
public interface BackendStore {
// Store name
public String store();
// Database name
public String database();
// Get the parent provider
public BackendStoreProvider provider();
// Open/close database
public void open(HugeConfig config);
public void close();
// Initialize/clear database
public void init();
public void clear();
// Add/delete data
public void mutate(BackendMutation mutation);
// Query data
public Iterator<BackendEntry> query(Query query);
// Transaction
public void beginTx();
public void commitTx();
public void rollbackTx();
// Get metadata by key
public <R> R metadata(HugeType type, String meta, Object[] args);
// Backend features
public BackendFeatures features();
// Generate an id for a specific type
public Id nextId(HugeType type);
}
2.1.3 Extending custom serializers
The serializer must inherit the abstract class: org.apache.hugegraph.backend.serializer.AbstractSerializer
( implements GraphSerializer, SchemaSerializer) The main interface is defined as follows:
public interface GraphSerializer {
public BackendEntry writeVertex(HugeVertex vertex);
public BackendEntry writeVertexProperty(HugeVertexProperty<?> prop);
public HugeVertex readVertex(HugeGraph graph, BackendEntry entry);
public BackendEntry writeEdge(HugeEdge edge);
public BackendEntry writeEdgeProperty(HugeEdgeProperty<?> prop);
public HugeEdge readEdge(HugeGraph graph, BackendEntry entry);
public BackendEntry writeIndex(HugeIndex index);
public HugeIndex readIndex(HugeGraph graph, ConditionQuery query, BackendEntry entry);
public BackendEntry writeId(HugeType type, Id id);
public Query writeQuery(Query query);
}
public interface SchemaSerializer {
public BackendEntry writeVertexLabel(VertexLabel vertexLabel);
public VertexLabel readVertexLabel(HugeGraph graph, BackendEntry entry);
public BackendEntry writeEdgeLabel(EdgeLabel edgeLabel);
public EdgeLabel readEdgeLabel(HugeGraph graph, BackendEntry entry);
public BackendEntry writePropertyKey(PropertyKey propertyKey);
public PropertyKey readPropertyKey(HugeGraph graph, BackendEntry entry);
public BackendEntry writeIndexLabel(IndexLabel indexLabel);
public IndexLabel readIndexLabel(HugeGraph graph, BackendEntry entry);
}
2.1.4 Extend custom configuration items
When adding a custom backend, it may be necessary to add new configuration items. The implementation process mainly includes:
- Add a configuration item container class and implement the interface
org.apache.hugegraph.config.OptionHolder - Provide a singleton method
public static OptionHolder instance(), and call the method when the object is initializedOptionHolder.registerOptions() - Add configuration item declaration, single-value configuration item type is
ConfigOption, multi-value configuration item type isConfigListOption
Take the RocksDB configuration item definition as an example:
public class RocksDBOptions extends OptionHolder {
private RocksDBOptions() {
super();
}
private static volatile RocksDBOptions instance;
public static synchronized RocksDBOptions instance() {
if (instance == null) {
instance = new RocksDBOptions();
instance.registerOptions();
}
return instance;
}
public static final ConfigOption<String> DATA_PATH =
new ConfigOption<>(
"rocksdb.data_path",
"The path for storing data of RocksDB.",
disallowEmpty(),
"rocksdb-data"
);
public static final ConfigOption<String> WAL_PATH =
new ConfigOption<>(
"rocksdb.wal_path",
"The path for storing WAL of RocksDB.",
disallowEmpty(),
"rocksdb-data"
);
public static final ConfigListOption<String> DATA_DISKS =
new ConfigListOption<>(
"rocksdb.data_disks",
false,
"The optimized disks for storing data of RocksDB. " +
"The format of each element: `STORE/TABLE: /path/to/disk`." +
"Allowed keys are [graph/vertex, graph/edge_out, graph/edge_in, " +
"graph/secondary_index, graph/range_index]",
null,
String.class,
ImmutableList.of()
);
}
2.2 Extend custom tokenizer
The tokenizer needs to implement the interface org.apache.hugegraph.analyzer.Analyzer, take implementing a SpaceAnalyzer space tokenizer as an example.
package org.apache.hugegraph.plugin;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
import org.apache.hugegraph.analyzer.Analyzer;
public class SpaceAnalyzer implements Analyzer {
@Override
public Set<String> segment(String text) {
return new HashSet<>(Arrays.asList(text.split(" ")));
}
}
3. Implement the plug-in interface and register it
The plug-in registration entry is HugeGraphPlugin.register(), the custom plug-in must implement this interface method, and register the extension
items defined above inside it. The interface org.apache.hugegraph.plugin.HugeGraphPlugin is defined as follows:
public interface HugeGraphPlugin {
public String name();
public void register();
public String supportsMinVersion();
public String supportsMaxVersion();
}
And HugeGraphPlugin provides 4 static methods for registering extensions:
- registerOptions(String name, String classPath): register configuration items
- registerBackend(String name, String classPath): register backend (BackendStoreProvider)
- registerSerializer(String name, String classPath): register serializer
- registerAnalyzer(String name, String classPath): register tokenizer
The following is an example of registering the SpaceAnalyzer tokenizer:
package org.apache.hugegraph.plugin;
public class DemoPlugin implements HugeGraphPlugin {
@Override
public String name() {
return "demo";
}
@Override
public void register() {
HugeGraphPlugin.registerAnalyzer("demo", SpaceAnalyzer.class.getName());
}
}
4. Configure SPI entry
- Make sure the services directory exists: hugegraph-plugin-demo/resources/META-INF/services
- Create a text file in the services directory: org.apache.hugegraph.plugin.HugeGraphPlugin
- The content of the file is as follows: org.apache.hugegraph.plugin.DemoPlugin
5. Make Jar package
Through maven packaging, execute the command in the project directory mvn package, and a Jar package file will be generated in the
target directory. Copy the Jar package to the plugins directory when using it, and restart the service to take effect.
4 - HugeGraph Toolchain Local Testing Guide
This guide helps developers run HugeGraph toolchain tests locally.
1. Core Concepts
1.1 Core Dependency: HugeGraph Server
Integration and functional tests of the toolchain depend on HugeGraph Server, including Client, Loader, Hubble, Spark Connector, Tools, and other components.
1.2 Test Types
- Unit Tests: Test individual functions/methods, no external dependencies required
- API Tests (ApiTestSuite): Test API interfaces, requires running HugeGraph Server
- Functional Tests (FuncTestSuite): End-to-end tests, require complete system environment
2. Environment Setup
2.1 System Requirements
- Operating System: Linux / macOS (Windows use WSL2)
- JDK: >= 11, configure
JAVA_HOME - Maven: >= 3.5
- Python: >= 3.11 (only required for Hubble tests)
2.2 Clone Code
git clone https://github.com/${GITHUB_USER_NAME}/hugegraph-toolchain.git
cd hugegraph-toolchain
3. Deploy Test Environment
Deployment Options
- Script Deployment (Recommended): Precisely control Server version by specifying Commit ID, avoid interface incompatibility
- Docker Deployment: Quick start, but may have version lag causing test failures
For detailed installation instructions, refer to Community Documentation
3.1 Script Deployment (Recommended)
Parameter Description
$COMMIT_ID: Specify Server source code Git Commit ID$DB_DATABASE/$DB_PASS: MySQL database name and password for Loader JDBC tests
Deployment Steps
1. Install HugeGraph Server
# Set version
export COMMIT_ID="master" # Or specific commit hash, e.g. "8b90977"
# Execute installation (script located in /assembly/travis/ directory)
hugegraph-client/assembly/travis/install-hugegraph-from-source.sh $COMMIT_ID
- Default ports: http 8080, https 8443
- Ensure ports are not occupied
2. Install Optional Dependencies
# Hadoop (only required for Loader HDFS tests)
hugegraph-loader/assembly/travis/install-hadoop.sh
# MySQL (only required for Loader JDBC tests)
hugegraph-loader/assembly/travis/install-mysql.sh $DB_DATABASE $DB_PASS
3. Health Check
curl http://localhost:8080/graphs
# Returns {"graphs":["hugegraph"]} indicates success
3.2 Docker Deployment
Note: Docker images may have version lag, use script deployment if encountering compatibility issues
Quick Start
docker network create hugegraph-net
docker run -itd --name=server -p 8080:8080 --network hugegraph-net hugegraph/hugegraph:latest
docker-compose Configuration (Optional)
Complete configuration example including Server, MySQL, Hadoop services (requires Docker Compose V2):
version: '3.8'
services:
hugegraph-server:
image: hugegraph/hugegraph:latest # Can be replaced with a specific version, or build your own image
container_name: hugegraph-server
ports:
- "8080:8080" # HugeGraph Server HTTP port
environment:
# Configure HugeGraph Server parameters as needed, e.g., backend storage
- HUGEGRAPH_SERVER_OPTIONS="-Dstore.backend=rocksdb"
volumes:
# If you need to persist data or mount configuration files, add volumes here
# - ./hugegraph-data:/opt/hugegraph/data
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/graphs || exit 1"]
interval: 10s
timeout: 3s
retries: 5
networks:
- hugegraph-net
# If you need JDBC tests for hugegraph-loader, you can add the following service
# mysql:
# image: mysql:5.7
# container_name: mysql-db
# environment:
# MYSQL_ROOT_PASSWORD: ${DB_PASS:-your_mysql_root_password} # Read from environment variable, or use default
# MYSQL_DATABASE: ${DB_DATABASE:-hugegraph_test_db} # Read from environment variable, or use default
# ports:
# - "3306:3306"
# volumes:
# - ./mysql-data:/var/lib/mysql # Data persistence
# healthcheck:
# test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-p${DB_PASS:-your_mysql_root_password}"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
# If you need Hadoop/HDFS tests for hugegraph-loader, you can add the following services
# namenode:
# image: johannestang/hadoop-namenode:2.0.0-hadoop2.8.5-java8
# container_name: namenode
# ports:
# - "0.0.0.0:9870:9870"
# - "0.0.0.0:8020:8020"
# environment:
# - CLUSTER_NAME=test-cluster
# - HDFS_NAMENODE_USER=root
# - HADOOP_CONF_DIR=/hadoop/etc/hadoop
# volumes:
# - ./config/core-site.xml:/hadoop/etc/hadoop/core-site.xml
# - ./config/hdfs-site.xml:/hadoop/etc/hadoop/hdfs-site.xml
# - namenode_data:/hadoop/dfs/name
# command: bash -c "if [ ! -d /hadoop/dfs/name/current ]; then hdfs namenode -format; fi && /entrypoint.sh"
# healthcheck:
# test: ["CMD", "hdfs", "dfsadmin", "-report"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
# datanode:
# image: johannestang/hadoop-datanode:2.0.0-hadoop2.8.5-java8
# container_name: datanode
# depends_on:
# - namenode
# environment:
# - CLUSTER_NAME=test-cluster
# - HDFS_DATANODE_USER=root
# - HADOOP_CONF_DIR=/hadoop/etc/hadoop
# volumes:
# - ./config/core-site.xml:/hadoop/etc/hadoop/core-site.xml
# - ./config/hdfs-site.xml:/hadoop/etc/hadoop/hdfs-site.xml
# - datanode_data:/hadoop/dfs/data
# healthcheck:
# test: ["CMD", "hdfs", "dfsadmin", "-report"]
# interval: 5s
# timeout: 3s
# retries: 5
# networks:
# - hugegraph-net
networks:
hugegraph-net:
driver: bridge
volumes:
namenode_data:
datanode_data:
Hadoop Configuration Mounts
Create a ./config folder in the same directory as docker-compose.yml to mount Hadoop configuration files. You can skip this step if HDFS testing is not required.
📁 ./config/core-site.xml content:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
</configuration>
📁 ./config/hdfs-site.xml content:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
Docker Operations
# Start services
docker compose up -d
# Check status
docker compose ps
lsof -i:8080 # Server
lsof -i:8020 # Hadoop
lsof -i:3306 # MySQL
# Stop services
docker compose down
4. Run Tests
Test process for each tool:
4.1 hugegraph-client
Compile
mvn -e compile -pl hugegraph-client -Dmaven.javadoc.skip=true -ntp
Dependent Services
Start HugeGraph Server (refer to Section 3)
Server Authentication Configuration
Note: Docker images <= 1.5.0 don’t support authentication tests, need 1.6.0+
ApiTest requires authentication configuration. Skip this if using script installation. Manual configuration needed for Docker:
# 1. Modify authentication mode
cp conf/rest-server.properties conf/rest-server.properties.backup
sed -i '/^auth.authenticator=/c\auth.authenticator=org.apache.hugegraph.auth.StandardAuthenticator' conf/rest-server.properties
grep auth.authenticator conf/rest-server.properties
# 2. Set password
# Note: Test code uses "pa" as default password, must match for tests to work
bin/stop-hugegraph.sh
export PASSWORD="pa" # Set to test default password
echo -e "${PASSWORD}" | bin/init-store.sh
bin/start-hugegraph.sh
Run Tests
# Check environment
curl http://localhost:8080/graphs # Should return {"graphs":["hugegraph"]}
curl -u admin:pa http://localhost:8080/graphs # Authentication test (pa is test default password)
# Run tests
cd hugegraph-client
mvn test -Dtest=UnitTestSuite -ntp # Unit tests
mvn test -Dtest=ApiTestSuite -ntp # API tests (requires Server)
mvn test -Dtest=FuncTestSuite -ntp # Functional tests (requires Server)
Check Server log if tests fail:
logs/hugegraph-server.log
4.2 hugegraph-loader
Compile
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
Dependent Services
- Required: HugeGraph Server
- Optional: Hadoop (HDFS tests), MySQL (JDBC tests)
Run Tests
cd hugegraph-loader
mvn test -P unit -ntp # Unit tests
mvn test -P file -ntp # File tests (requires Server)
mvn test -P hdfs -ntp # HDFS tests (requires Server + Hadoop)
mvn test -P jdbc -ntp # JDBC tests (requires Server + MySQL)
mvn test -P kafka -ntp # Kafka tests (requires Server)
4.3 hugegraph-hubble
Compile
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
cd hugegraph-hubble
mvn -e compile -Dmaven.javadoc.skip=true -ntp
Dependent Services
1. Start Server (refer to Section 3)
2. Python Environment
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
python -m pip install -r hubble-dist/assembly/travis/requirements.txt
3. Build and Verify
mvn package -Dmaven.test.skip=true
# Optional: Start and verify
# Compatible with both historical (-incubating-) and TLP package naming
cd apache-hugegraph-hubble*/bin
./start-hubble.sh -d && sleep 10
curl http://localhost:8088/api/health
./stop-hubble.sh
Run Tests
# Unit tests
mvn test -P unit-test -pl hugegraph-hubble/hubble-be -ntp
# API tests (requires Server + Hubble running)
curl http://localhost:8080/graphs # Check Server
curl http://localhost:8088/api/health # Check Hubble
cd hugegraph-hubble/hubble-dist
./assembly/travis/run-api-test.sh
4.4 hugegraph-spark-connector
Compile
mvn install -pl hugegraph-client,hugegraph-spark-connector -am -Dmaven.javadoc.skip=true -DskipTests -ntp
Run Tests
cd hugegraph-spark-connector
mvn test -ntp # Requires Server running
4.5 hugegraph-tools
Compile
mvn install -pl hugegraph-client,hugegraph-tools -am -Dmaven.javadoc.skip=true -DskipTests -ntp
Run Tests
cd hugegraph-tools
mvn test -Dtest=FuncTestSuite -ntp # Requires Server running
5. Common Issues
Service Connection Issues
Symptoms: Cannot connect to Server/MySQL/Hadoop
Troubleshooting:
- Confirm services are running (Server must be on port 8080)
- Check port usage:
lsof -i:8080 - Docker check:
docker compose psanddocker compose logs
Configuration Issues
Symptoms: File not found, parameter errors
Troubleshooting:
- Check environment variables:
echo $COMMIT_ID - Script permissions:
chmod +x hugegraph-*/assembly/travis/*.sh
HDFS Test Failures
Troubleshooting:
- Confirm NameNode/DataNode running normally
- Check Hadoop logs
- Verify HDFS connection:
hdfs dfsadmin -report
JDBC Test Failures
Troubleshooting:
- Confirm MySQL running normally
- Verify database connection:
mysql -u root -p$DB_PASS - Check MySQL logs
6. References
- HugeGraph GitHub Repository: https://github.com/apache/hugegraph
- HugeGraph Toolchain GitHub Repository: https://github.com/apache/hugegraph-toolchain
- HugeGraph Server Official Documentation: https://hugegraph.apache.org/docs/quickstart/hugegraph/hugegraph-server/
- CI Script Path:
.github/workflows/*-ci.yml(CI configuration files in the HugeGraph toolchain project, which can be used as a reference) - Dependent Service Installation Scripts:
hugegraph-*/assembly/travis/(Installation scripts for CI and local testing in the HugeGraph toolchain project, can be used directly or as a reference)
5 - Backup and Restore
Description
Backup and Restore are functions of backup map and restore map. The data backed up and restored includes metadata (schema) and graph data (vertex and edge).
Backup
Export the metadata and graph data of a graph in the HugeGraph system in JSON format.
Restore
Re-import the data in JSON format exported by Backup to a graph in the HugeGraph system.
Restore has two modes:
- In Restoring mode, the metadata and graph data exported by Backup are restored to the HugeGraph system intact. It can be used for graph backup and recovery, and the general target graph is a new graph (without metadata and graph data). for example:
- System upgrade, first back up the map, then upgrade the system, and finally restore the map to the new system
- Graph migration, from a HugeGraph system, use the Backup function to export the graph, and then use the Restore function to import the graph into another HugeGraph system
- In the Merging mode, the metadata and graph data exported by Backup are imported into another graph that already has metadata or graph data. During the process, the ID of the metadata may change, and the IDs of vertices and edges will also change accordingly.
- Can be used to merge graphs
Instructions
You can use hugegraph-tools to backup and restore the graph.
Backup
bin/hugegraph backup -t all -d data
This command backs up all the metadata and graph data of the hugegraph graph of http://127.0.0.1 to the data directory.
Backup works fine in all three graph modes
Restore
Restore has two modes: RESTORING and MERGING. Before backup, you must first set the graph mode according to your needs.
Step 1: View and set graph mode
bin/hugegraph graph-mode-get
This command is used to view the current graph mode, including: NONE, RESTORING, MERGING.
bin/hugegraph graph-mode-set -m RESTORING
This command is used to set the graph mode. Before Restore, it can be set to RESTORING or MERGING mode. In the example, it is set to RESTORING.
Step 2: Restore data
bin/hugegraph restore -t all -d data
This command re-imports all metadata and graph data in the data directory to the hugegraph graph at http://127.0.0.1.
Step 3: Restoring Graph Mode
bin/hugegraph graph-mode-set -m NONE
This command is used to restore the graph mode to NONE.
So far, a complete graph backup and graph recovery process is over.
help
For detailed usage of backup and restore commands, please refer to the hugegraph-tools documentation.
API description for Backup/Restore usage and implementation
Backup
Backup uses the corresponding list(GET) API export of metadata and graph data, and no new API is added.
Restore
Restore uses the corresponding create(POST) API imports for metadata and graph data, and does not add new APIs.
There are two different modes for Restore: Restoring and Merging. In addition, there is a regular mode of NONE (default), the differences are as follows:
- In None mode, the writing of metadata and graph data is normal, please refer to the function description. special:
- ID is not allowed when metadata (schema) is created
- Graph data (vertex) is not allowed to specify an ID when the id strategy is Automatic
- Restoring mode, restoring to a new graph, in particular:
- ID is allowed to be specified when metadata (schema) is created
- Graph data (vertex) allows specifying an ID when the id strategy is Automatic
- Merging mode, merging into a graph with existing metadata and graph data, in particular:
- ID is not allowed when metadata (schema) is created
- Graph data (vertex) allows specifying an ID when the id strategy is Automatic
Normally, the graph mode is None. When you need to restore the graph, you need to temporarily change the graph mode to Restoring mode or Merging mode as needed, and when the Restore is completed, restore the graph mode to None.
The implemented RESTful API for setting graph mode is as follows:
View the schema of a graph. This operation requires administrator privileges
Method & Url
GET http://localhost:8080/graphs/{graph}/mode
Response Status
200
Response Body
{
"mode": "NONE"
}
Legal graph modes include: NONE, RESTORING, MERGING
Set the mode of a graph. ““This operation requires administrator privileges**
Method & Url
PUT http://localhost:8080/graphs/{graph}/mode
Request Body
"RESTORING"
Legal graph modes include: NONE, RESTORING, MERGING
Response Status
200
Response Body
{
"mode": "RESTORING"
}
6 - HugeGraph Docker Cluster Guide
Overview
HugeGraph can quickly run a full distributed deployment (PD + Store + Server) with Docker Compose. This works on Linux and Mac.
Prerequisites
- Docker Engine 20.10+ or Docker Desktop 4.x+
- Docker Compose v2
- For a 3-node cluster on Mac: allocate at least 12 GB memory (Settings → Resources → Memory). Adjust this on other platforms as needed.
Tested environments: Linux (native Docker) and macOS (Docker Desktop with ARM M4).
Compose Files
Three compose files are available in the docker/ directory of the HugeGraph main repository:
| File | Description |
|---|---|
docker-compose.yml | Quickstart for a single-host deployment using pre-built images |
docker-compose.dev.yml | Development mode for a single-host deployment built from source |
docker-compose-3pd-3store-3server.yml | Distributed cluster with 3 PD, 3 Store, and 3 Server processes |
Note: The following steps assume you have already cloned or pulled the HugeGraph main repository locally, or at least have its
docker/directory available.
Single-Node Quickstart
cd hugegraph/docker
# Keep the version aligned with the latest release, for example 1.x.0
HUGEGRAPH_VERSION=1.7.0 docker compose up -d
Verify:
curl http://localhost:8080/versions
3-Node Cluster Quickstart
cd hugegraph/docker
HUGEGRAPH_VERSION=1.7.0 docker compose -f docker-compose-3pd-3store-3server.yml up -d
Built-in startup ordering:
- PD nodes start first and must pass the
/v1/healthcheck - Store nodes start only after all PD nodes are healthy
- Server nodes start last, after all PD and Store nodes are healthy
Verify that the cluster is healthy:
curl http://localhost:8620/v1/health # PD health
curl http://localhost:8520/v1/health # Store health
curl http://localhost:8080/versions # Server
curl http://localhost:8620/v1/stores # Registered stores
curl http://localhost:8620/v1/partitions # Partition assignment
Environment Variable Reference
PD Variables
| Variable | Required | Default | Maps To |
|---|---|---|---|
HG_PD_GRPC_HOST | Yes | — | grpc.host |
HG_PD_RAFT_ADDRESS | Yes | — | raft.address |
HG_PD_RAFT_PEERS_LIST | Yes | — | raft.peers-list |
HG_PD_INITIAL_STORE_LIST | Yes | — | pd.initial-store-list |
HG_PD_GRPC_PORT | No | 8686 | grpc.port |
HG_PD_REST_PORT | No | 8620 | server.port |
HG_PD_DATA_PATH | No | /hugegraph-pd/pd_data | pd.data-path |
HG_PD_INITIAL_STORE_COUNT | No | 1 | pd.initial-store-count |
Deprecated aliases:
GRPC_HOST→HG_PD_GRPC_HOST,RAFT_ADDRESS→HG_PD_RAFT_ADDRESS,RAFT_PEERS→HG_PD_RAFT_PEERS_LIST
Store Variables
| Variable | Required | Default | Maps To |
|---|---|---|---|
HG_STORE_PD_ADDRESS | Yes | — | pdserver.address |
HG_STORE_GRPC_HOST | Yes | — | grpc.host |
HG_STORE_RAFT_ADDRESS | Yes | — | raft.address |
HG_STORE_GRPC_PORT | No | 8500 | grpc.port |
HG_STORE_REST_PORT | No | 8520 | server.port |
HG_STORE_DATA_PATH | No | /hugegraph-store/storage | app.data-path |
Deprecated aliases:
PD_ADDRESS→HG_STORE_PD_ADDRESS,GRPC_HOST→HG_STORE_GRPC_HOST,RAFT_ADDRESS→HG_STORE_RAFT_ADDRESS
Server Variables
| Variable | Required | Default | Maps To |
|---|---|---|---|
HG_SERVER_BACKEND | Yes | — | backend in hugegraph.properties |
HG_SERVER_PD_PEERS | Yes | — | pd.peers |
STORE_REST | No | — | used by wait-partition.sh |
PASSWORD | No | — | enables auth mode |
Deprecated aliases:
BACKEND→HG_SERVER_BACKEND,PD_PEERS→HG_SERVER_PD_PEERS
Port Reference
| Service | Host Port | Purpose |
|---|---|---|
| pd0 | 8620 | REST API |
| pd0 | 8686 | gRPC |
| pd1 | 8621 | REST API |
| pd1 | 8687 | gRPC |
| pd2 | 8622 | REST API |
| pd2 | 8688 | gRPC |
| store0 | 8500 | gRPC |
| store0 | 8520 | REST API |
| store1 | 8501 | gRPC |
| store1 | 8521 | REST API |
| store2 | 8502 | gRPC |
| store2 | 8522 | REST API |
| server0 | 8080 | Graph API |
| server1 | 8081 | Graph API |
| server2 | 8082 | Graph API |
Troubleshooting
Containers exit due to OOM (
exit code 137): Increase Docker Desktop memory to at least 12 GB, or reduce the JVM heap settings for the process that is being killed.Raft leader election timeout: Check that
HG_PD_RAFT_PEERS_LISTis identical on all PD nodes. Verify connectivity withdocker exec hg-pd0 ping pd1.Partition assignment does not complete: Check
curl http://localhost:8620/v1/storesand confirm that all 3 stores show"state":"Up"before partition assignment can finish.Connection refused: Ensure
HG_*environment variables use container hostnames (pd0,store0) instead of127.0.0.1.
Viewing runtime logs: Use docker logs <container-name> (e.g. docker logs hg-pd0) to view logs directly without exec-ing into the container.
Container Supervision & Health Checks
Version note: This behavior is not present in the
1.7.0images. UseHUGEGRAPH_VERSION=latestor wait for the next release tag.
Process Supervision Model
Previously, all three Docker entrypoints ended with tail -f /dev/null, which kept the container running even if the Java process crashed. Docker’s restart: unless-stopped policy never fired because the container never exited.
The entrypoints now supervise Java directly:
- PD and Store containers: the entrypoint passes
-d falseto the startup script, whichexecs Java directly. The container process IS the Java process — when Java exits (crash or clean shutdown), the container exits immediately and Docker’s restart policy fires. - Server container: the entrypoint uses
tail --pid=$PID -f /dev/nullto block until Java exits. ASIGTERM/SIGINTtrap forwardsdocker stopsignals to Java and waits for clean shutdown (exits 0). If Java crashes, the entrypoint exits 1 so the restart policy fires. dumb-init(PID 1 in all images) forwards signals from Docker to the entrypoint process.
Health Check Endpoints
All four Docker images now include a HEALTHCHECK instruction. docker ps shows real health status. During the 90-second start period, failed checks do not count. After that, three consecutive failures mark the container as unhealthy.
| Image | Health endpoint | Port | Parameters |
|---|---|---|---|
hugegraph/hugegraph (server) | GET /versions | 8080 | --interval=15s --timeout=10s --start-period=90s --retries=3 |
hugegraph/hugegraph-hstore | GET /versions | 8080 | same |
hugegraph/hugegraph-pd | GET /v1/health | 8620 | same |
hugegraph/hugegraph-store | GET /v1/health | 8520 | same |
Note: The
-m trueflag (cron-based monitor) instart-hugegraph.shis for VM/bare-metal deployments only. It is not installed or used in Docker images. Docker users should rely on the built-inHEALTHCHECKand Docker’s restart policy instead.
7 - FAQ
How to choose the back-end storage? RocksDB or distributed storage?
HugeGraph supports multiple deployment modes. Choose based on your data scale and scenario:
- Standalone Mode: Server + RocksDB, suitable for development/testing and small to medium-scale data (< 4TB)
- Distributed Mode: HugeGraph-PD + HugeGraph-Store (HStore), supports horizontal scaling and high availability (< 1000TB data scale), suitable for production environments and large-scale graph data applications
Note: Cassandra, HBase, MySQL and other backends are only available in HugeGraph <= 1.5 versions and are no longer maintained by the official team
Prompt when starting the service:
xxx (core dumped) xxxPlease check if the JDK version is Java 11, at least Java 8 is required
The service is started successfully, but there is a prompt similar to “Unable to connect to the backend or the connection is not open” when operating the graph
init-storeBefore starting the service for the first time, you need to use the initialization backend first , and subsequent versions will prompt more clearly and directly.
Do all backends need to be executed before use init-store, and can the serialization options be filled in at will?
Before running the
init-store.shcommand to create the databases that will host the graphs defined in the configuration file, the back-end must be properly configured and running. The only exception is when using memory as the back-end. Supported back-ends includecassandra,hbase,rocksdb,scylladb, etc. It’s important to note that serialization must maintain a strict one-to-one correspondence and cannot be assigned differntly than the recommended values.Execution
init-storeerror:Exception in thread "main" java.lang.UnsatisfiedLinkError: /tmp/librocksdbjni3226083071221514754.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.10' not found (required by /tmp/librocksdbjni3226083071221514754.so)RocksDB requires gcc 4.3.0 (GLIBCXX_3.4.10) and above
The error
NoHostAvailableExceptionoccurred while executinginit-store.sh.NoHostAvailableExceptionmeans that theCassandraservice cannot be connected to. If you are sure that you want to use the Cassandra backend, please install and start this service first. As for the message itself, it may not be clear enough, and we will update the documentation to provide further explanation.The
bindirectory containsstart-hugegraph.sh,start-restserver.shandstart-gremlinserver.sh. These scripts seem to be related to startup. Which one should be used?Since version 0.3.3, GremlinServer and RestServer have been merged into HugeGraphServer. To start, use start-hugegraph.sh. The latter two will be removed in future versions.
Two graphs are configured, the names are
hugegraphandhugegraph1, and the command to start the service isstart-hugegraph.sh. Is only the hugegraph graph opened?start-hugegraph.shwill open all graphs under the graphs ofgremlin-server.yaml. The two have no direct relationship in nameAfter the service starts successfully, garbled characters are returned when using
curlto query all verticesThe batch vertices/edges returned by the server are compressed (gzip), and can be redirected to
gunzipfor decompression (curl http://example | gunzip), or can be sent with thepostmanofFirefoxor therestletplug-in of Chrome browser. request, the response data will be decompressed automatically.When using the vertex Id to query the vertex through the
RESTful API, it returns empty, but the vertex does existCheck the type of the vertex ID. If it is a string type, the “id” part of the API URL needs to be enclosed in double quotes, while for numeric types, it is not necessary to enclose the ID in quotes.
Vertex Id has been double quoted as required, but querying the vertex via the RESTful API still returns empty
Check whether the vertex id contains
+,space,/,?,%,&, and=reserved characters of theseURLs. If they exist, they need to be encoded. The following table gives the coded values:special character | encoded value ------------------| ------------- + | %2B space | %20 / | %2F ? | %3F % | %25 # | %23 & | %26 = | %3DTimeout when querying vertices or edges of a certain category (
query by label)Since the amount of data belonging to a certain label may be relatively large, please add a limit limit.
It is possible to operate the graph through the
RESTful API, but when sendingGremlinstatements, an error is reported:Request Failed(500)It may be that the configuration of
GremlinServeris wrong, check whether thehostandportofgremlin-server.yamlmatch thegremlinserver.urlofrest-server.properties, if they do not match, modify them, and then Restart the service.When using
Loaderto import data, aSocket Timeoutexception occurs, and thenLoaderis interruptedContinuously importing data will put too much pressure on the
Server, which will cause some requests to time out. The pressure onServercan be appropriately relieved by adjusting the parameters ofLoader(such as: number of retries, retry interval, error tolerance, etc.), and reduce the frequency of this problem.How to delete all vertices and edges. There is no such interface in the RESTful API. Calling
g.V().drop()ofgremlinwill report an errorVertices in transaction have reached capacity xxxAt present, there is really no good way to delete all the data. If the user deploys the
Serverand the backend by himself, he can directly clear the database and restart theServer. You can use the paging API or scan API to get all the data first, and then delete them one by one.The database has been cleared and
init-storehas been executed, but when trying to add a schema, the prompt “xxx has existed” appeared.There is a cache in the
HugeGraphServer, and it is necessary to restart theServerwhen the database is cleared, otherwise the residual cache will be inconsistent.An error is reported during the process of inserting vertices or edges:
Id max length is 128, but got xxx {yyy}orBig id max length is 32768, but got xxxIn order to ensure query performance, the current backend storage limits the length of the id column. The vertex id cannot exceed 128 bytes, the edge id cannot exceed 32768 bytes, and the index id cannot exceed 128 bytes.
Is there support for nested attributes, and if not, are there any alternatives?
Nested attributes are currently not supported. Alternative: Nested attributes can be taken out as individual vertices and connected with edges.
Can an
EdgeLabelconnect multiple pairs ofVertexLabel, such as “investment” relationship, which can be “individual” investing in “enterprise”, or “enterprise” investing in “enterprise”?An
EdgeLabeldoes not support connecting multiple pairs ofVertexLabels, users need to split theEdgeLabelinto finer details, such as: “personal investment”, “enterprise investment”.Prompt
HTTP 415 Unsupported Media Typewhen sending a request throughRestAPIContent-Type: application/jsonneeds to be specified in the request header
Other issues can be searched in the issue area of the corresponding project, such as Server-Issues / Loader Issues
8 - Security Report
Reporting New Security Problems with Apache HugeGraph
⚠️ SEC Reminder: Notice to Vulnerability Researchers Regarding Graph Query Languages
Given the inherent parsing and execution flexibility of graph query languages (like Gremlin/Cypher), HugeGraph strongly recommends relying on the "Auth (Authentication) + IP Whitelist + Audit Log" mechanism in production environments to adhere to the Principle of Least Privilege. Furthermore, since Server nodes are essentially stateless, it is explicitly advised to use Containerized Environments (Docker/K8s) for isolated deployments in all production environments.
Recently, the community has received numerous security reports concerning the flexibility of graph queries. Until the overall HugeGraph security architecture is fully refactored, known situations involving the execution of DSL queries with Auth disabled or skipped, or by using an anonymous or unauthorized identity will no longer be treated individually as new vulnerabilities.
However, if a vulnerability can still be exploited in an environment where the Auth system is enabled by accessing it with an anonymous or unauthorized identity, or if one successfully bypasses the IP whitelist / escapes the container causing severe unauthorized access or underlying system destruction, we still consider this a high-risk security vulnerability and highly encourage you to report it to us at any time!
Adhering to the specifications of ASF, the HugeGraph community maintains a highly proactive and open attitude towards addressing security issues in the remediation projects.
We strongly recommend that users first report such issues to our dedicated security email list, with detailed procedures specified in the ASF SEC code of conduct.
Please note that the security email group is reserved for reporting undisclosed security vulnerabilities and following up on the vulnerability resolution process.
Regular software Bug/Error reports should be directed to Github Issue/Discussion or the HugeGraph-Dev email group. Emails sent to the security list that are unrelated to security issues will be ignored.
The independent security email (group) address is: security@hugegraph.apache.org
The general process for handling security vulnerabilities is as follows:
- The reporter privately reports the vulnerability to the Apache HugeGraph SEC email group (including as much information as possible, such as reproducible versions, relevant descriptions, reproduction methods, and the scope of impact)
- The HugeGraph project security team collaborates privately with the reporter to discuss the vulnerability resolution (after preliminary confirmation, a
CVEnumber can be requested for registration) - The project creates a new version of the software package affected by the vulnerability to provide a fix
- At an appropriate time, a general description of the vulnerability and how to apply the fix will be publicly disclosed (in compliance with ASF standards, the announcement should not disclose sensitive information such as reproduction details)
- Official CVE release and related procedures follow the ASF-SEC page
Known Security Vulnerabilities (CVEs)
HugeGraph main project (Server/PD/Store)
- CVE-2024-27348: HugeGraph-Server - Command execution in gremlin
- CVE-2024-27349: HugeGraph-Server - Bypass whitelist in Auth mode
- CVE-2024-43441: HugeGraph-Server - Fixed JWT Token (Secret)
- CVE-2025-26866: HugeGraph-Server - RAFT and deserialization vulnerability
HugeGraph-Toolchain project (Hubble/Loader/Client/Tools/..)
- CVE-2024-27347: HugeGraph-Hubble - SSRF in Hubble connection page