HugeGraph Architecture Overview
1 Overview
As a full-stack graph system covering Graph Database, Graph Computing, and Graph AI, HugeGraph is centered around a high-performance graph engine (HugeGraph Server) and supports both OLTP and OLAP graph computation types. For the OLTP layer, it implements the Apache TinkerPop3 framework and supports the Gremlin and Cypher query languages. It comes with a complete application toolchain and provides a pluggable backend storage driver framework.
Below is the overall architecture diagram of HugeGraph:
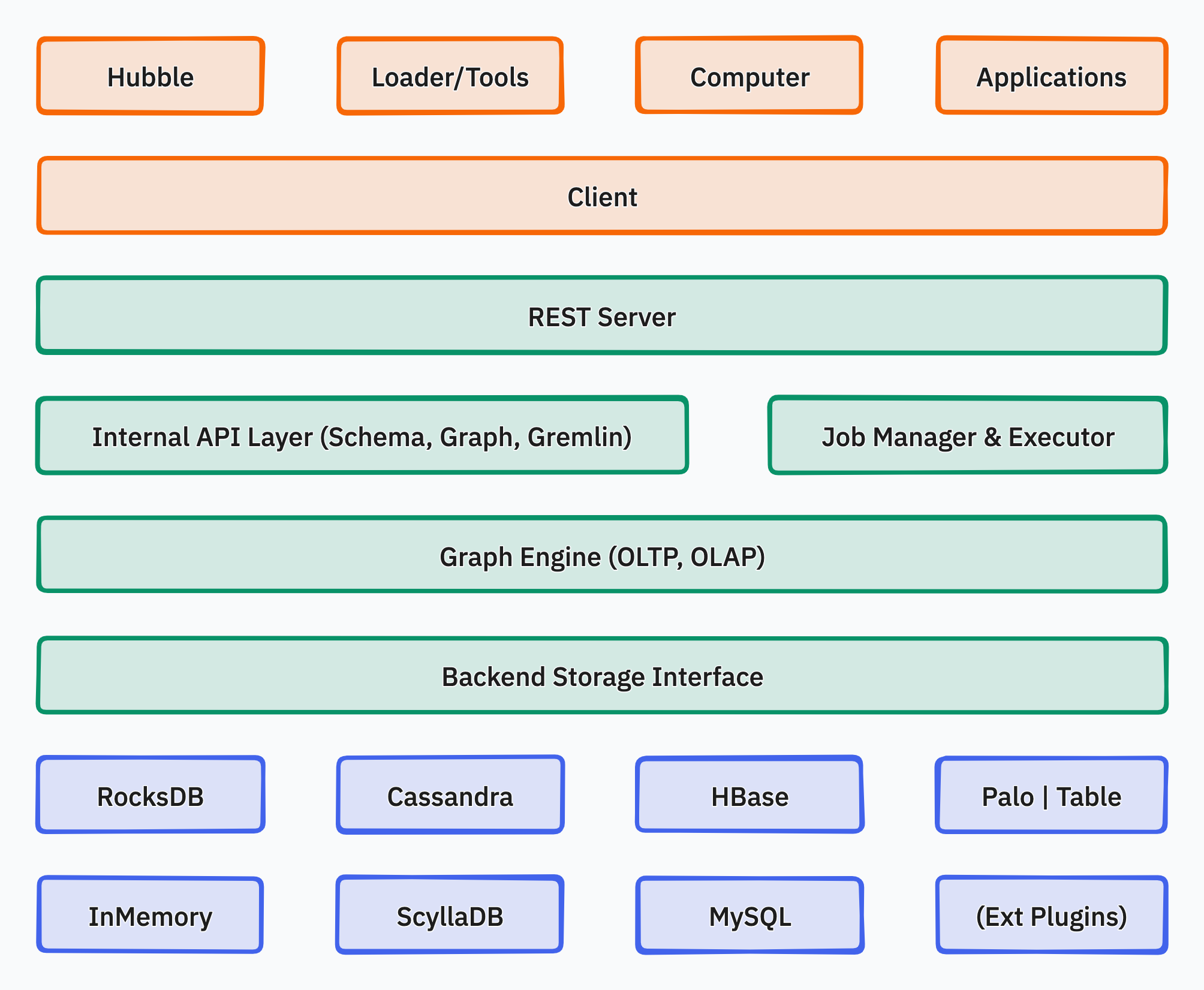
HugeGraph consists of three layers of functionality: the application layer, the graph engine layer, and the storage layer.
- Application Layer:
- Hubble: A one-stop visual analysis platform that covers the entire process from data modeling to rapid data import, online and offline analysis, and unified graph management, realizing wizard-style operations for the entire graph application process.
- Loader: A data import component that can transform data from multiple data sources into graph vertices and edges and batch import them into the graph database.
- Tools: Command-line tools for deploying, managing, and backing up/restoring data in HugeGraph.
- Computer: A distributed graph processing system (OLAP), which is an implementation of Pregel and can run on Kubernetes.
- Client: A HugeGraph client written in Java. Users can use the Client to write Java code to operate HugeGraph. Python, Go, C++ and other language support will be provided in the future as needed.
- Graph Engine Layer:
- REST Server: Provides a RESTful API for querying graph/schema information, supports the Gremlin and Cypher query languages, and offers APIs for service monitoring and operations.
- Graph Engine: Supports both OLTP and OLAP graph computation types, with OLTP implementing the Apache TinkerPop3 framework.
- Backend Interface: Implements the storage of graph data to the backend.
- Storage Layer:
- Storage Backend: Supports multiple built-in storage backends (RocksDB/MySQL/HBase/…) and allows users to extend custom backends without modifying the existing source code.
Page last updated March 9, 2026: docs: describe HugeGraph as full-stack graph system (#456) (5a3027b0)