HugeGraph-Hubble Quick Start
1 HugeGraph-Hubble Overview
Note: The current version of Hubble has not yet added Auth/Login related interfaces and standalone protection, it will be added in the next Release version (> 1.5). Please be careful not to expose it in a public network environment or untrusted networks to avoid related SEC issues (you can also use IP & port whitelist + HTTPS)
HugeGraph-Hubble is HugeGraph’s one-stop visual analysis platform. The platform covers the whole process from data modeling, to efficient data import, to real-time and offline analysis of data, and unified management of graphs, realizing the whole process wizard of graph application. It is designed to improve the user’s use fluency, lower the user’s use threshold, and provide a more efficient and easy-to-use user experience.
The platform mainly includes the following modules:
Graph Management
The graph management module realizes the unified management of multiple graphs and graph access, editing, deletion, and query by creating graph and connecting the platform and graph data.
Metadata Modeling
The metadata modeling module realizes the construction and management of graph models by creating attribute libraries, vertex types, edge types, and index types. The platform provides two modes, list mode and graph mode, which can display the metadata model in real time, which is more intuitive. At the same time, it also provides a metadata reuse function across graphs, which saves the tedious and repetitive creation process of the same metadata, greatly improves modeling efficiency and enhances ease of use.
Graph Analysis
By inputting the graph traversal language Gremlin, high-performance general analysis of graph data can be realized, and functions such as customized multidimensional path query of vertices can be provided, and three kinds of graph result display methods are provided, including: graph form, table form, Json form, and multidimensional display. The data form meets the needs of various scenarios used by users. It provides functions such as running records and collection of common statements, realizing the traceability of graph operations, and the reuse and sharing of query input, which is fast and efficient. It supports the export of graph data, and the export format is JSON format.
Task Management
For Gremlin tasks that need to traverse the whole graph, index creation and reconstruction, and other time-consuming asynchronous tasks, the platform provides corresponding task management functions to achieve unified management and result viewing of asynchronous tasks.
Data Import
“Note: The data import function is currently suitable for preliminary use. For formal data import, please use hugegraph-loader, which has much better performance, stability, and functionality.”
Data import is to convert the user’s business data into the vertices and edges of the graph and insert it into the graph database. The platform provides a wizard-style visual import module. By creating import tasks, the management of import tasks and the parallel operation of multiple import tasks are realized. Improve import performance. After entering the import task, you only need to follow the platform step prompts, upload files as needed, and fill in the content to easily implement the import process of graph data. At the same time, it supports breakpoint resuming, error retry mechanism, etc., which reduces import costs and improves efficiency.
2 Deploy
There are three ways to deploy hugegraph-hubble
- Use Docker (Convenient for Test/Dev)
- Download the Toolchain binary package
- Source code compilation
2.1 Use docker (Convenient for Test/Dev)
Special Note: If you are starting
hubblewith Docker, andhubbleand the server are on the same host. When configuring the hostname for the graph on the Hubble web page, please do not directly set it tolocalhost/127.0.0.1. This will refer to thehubblecontainer internally rather than the host machine, resulting in a connection failure to the server.If
hubbleandserveris in the same docker network, we recommend using thecontainer_name(in our example, it isserver) as the hostname, and8080as the port. Or you can use the host IP as the hostname, and the port is configured by the host for the server.
We can use docker run -itd --name=hubble -p 8088:8088 hugegraph/hubble:1.5.0 to quick start hubble.
Alternatively, you can use Docker Compose to start hubble. Additionally, if hubble and the graph is in the same Docker network, you can access the graph using the container name of the graph, eliminating the need for the host machine’s IP address.
Use docker-compose up -d,docker-compose.yml is following:
version: '3'
services:
server:
image: hugegraph/hugegraph:1.5.0
container_name: server
ports:
- 8080:8080
hubble:
image: hugegraph/hubble:1.5.0
container_name: hubble
ports:
- 8088:8088
Note:
The docker image of hugegraph-hubble is a convenience release to start hugegraph-hubble quickly, but not official distribution artifacts. You can find more details from ASF Release Distribution Policy.
Recommend to use
release tag(like1.5.0) for the stable version. Uselatesttag to experience the newest functions in development.
2.2 Download the Toolchain binary package
hubble is in the toolchain project. First, download the binary tar tarball
wget https://downloads.apache.org/incubator/hugegraph/{version}/apache-hugegraph-toolchain-incubating-{version}.tar.gz
tar -xvf apache-hugegraph-toolchain-incubating-{version}.tar.gz
cd apache-hugegraph-toolchain-incubating-{version}.tar.gz/apache-hugegraph-hubble-incubating-{version}
Run hubble
bin/start-hubble.sh
Then, we can see:
starting HugeGraphHubble ..............timed out with http status 502
2023-08-30 20:38:34 [main] [INFO ] o.a.h.HugeGraphHubble [] - Starting HugeGraphHubble v1.0.0 on cpu05 with PID xxx (~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0/lib/hubble-be-1.0.0.jar started by $USER in ~/apache-hugegraph-toolchain-incubating-1.0.0/apache-hugegraph-hubble-incubating-1.0.0)
...
2023-08-30 20:38:38 [main] [INFO ] c.z.h.HikariDataSource [] - hugegraph-hubble-HikariCP - Start completed.
2023-08-30 20:38:41 [main] [INFO ] o.a.c.h.Http11NioProtocol [] - Starting ProtocolHandler ["http-nio-0.0.0.0-8088"]
2023-08-30 20:38:41 [main] [INFO ] o.a.h.HugeGraphHubble [] - Started HugeGraphHubble in 7.379 seconds (JVM running for 8.499)
Then use a web browser to access ip:8088 and you can see the Hubble page. You can stop the service using bin/stop-hubble.sh.
2.3 Source code compilation
Note: The plugin frontend-maven-plugin has been added to hugegraph-hubble/hubble-be/pom.xml. To compile hubble, you do not need to install Nodejs V16.x and yarn environment in your local environment in advance. You can directly execute the following steps.
Download the toolchain source code.
git clone https://github.com/apache/hugegraph-toolchain.git
Compile hubble. It depends on the loader and client, so you need to build these dependencies in advance during the compilation process (you can skip this step later).
cd hugegraph-toolchain
sudo pip install -r hugegraph-hubble/hubble-dist/assembly/travis/requirements.txt
mvn install -pl hugegraph-client,hugegraph-loader -am -Dmaven.javadoc.skip=true -DskipTests -ntp
cd hugegraph-hubble
mvn -e compile package -Dmaven.javadoc.skip=true -Dmaven.test.skip=true -ntp
cd apache-hugegraph-hubble-incubating*
Run hubble
bin/start-hubble.sh -d
3 Platform Workflows
The module usage process of the platform is as follows:

4 Platform Instructions
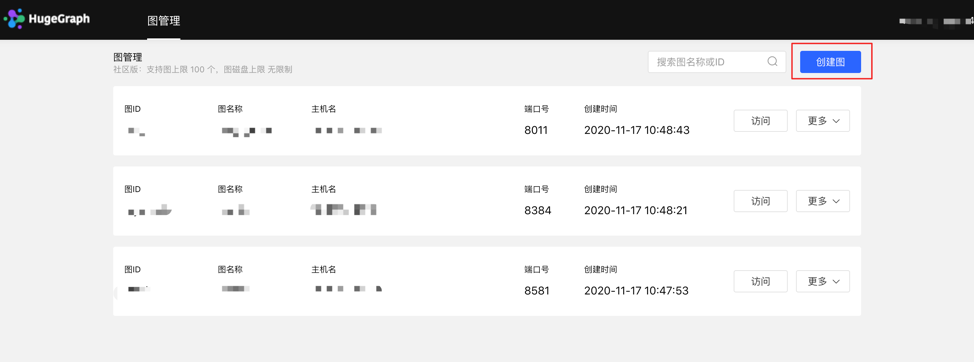
4.1 Graph Management
4.1.1 Graph creation
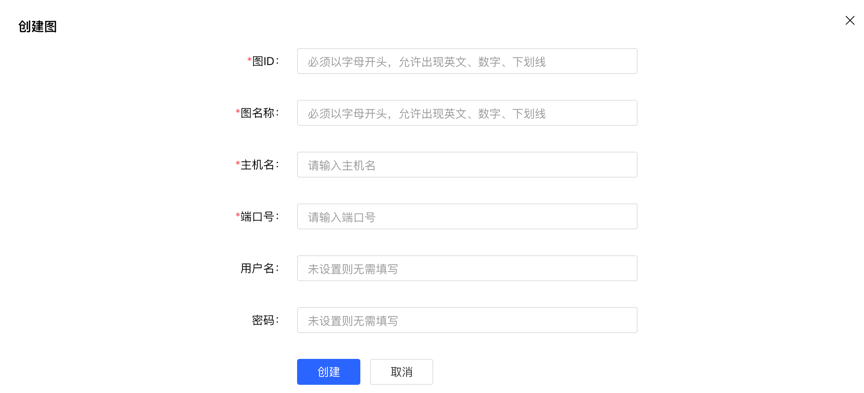
Under the graph management module, click [Create graph], and realize the connection of multiple graphs by filling in the graph ID, graph name, host name, port number, username, and password information.
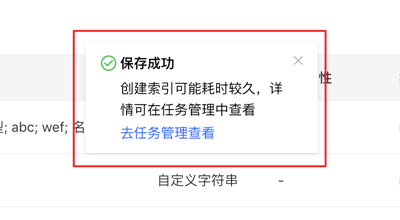
Create graph by filling in the content as follows:
Special Note: If you are starting
hubblewith Docker, andhubbleand the server are on the same host. When configuring the hostname for the graph on the Hubble web page, please do not directly set it tolocalhost/127.0.0.1. Ifhubbleandserveris in the same docker network, we recommend using thecontainer_name(in our example, it isgraph) as the hostname, and8080as the port. Or you can use the host IP as the hostname, and the port is configured by the host for the server.
4.1.2 Graph Access
Realize the information access to the graph space. After entering, you can perform operations such as multidimensional query analysis, metadata management, data import, and algorithm analysis of the graph.

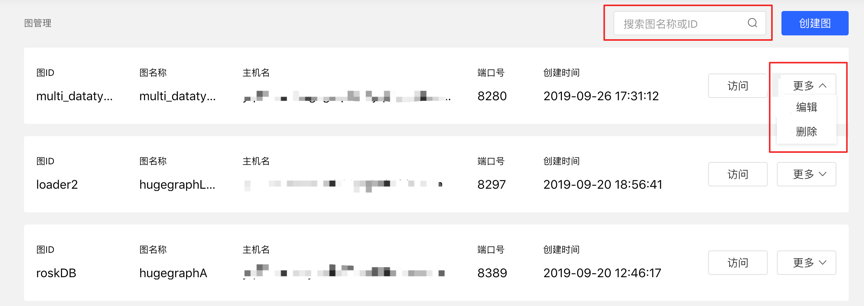
4.1.3 Graph management
- Users can achieve unified management of graphs through overview, search, and information editing and deletion of single graphs.
- Search range: You can search for the graph name and ID.
4.2 Metadata Modeling (list + graph mode)
4.2.1 Module entry
Left navigation:
4.2.2 Property type
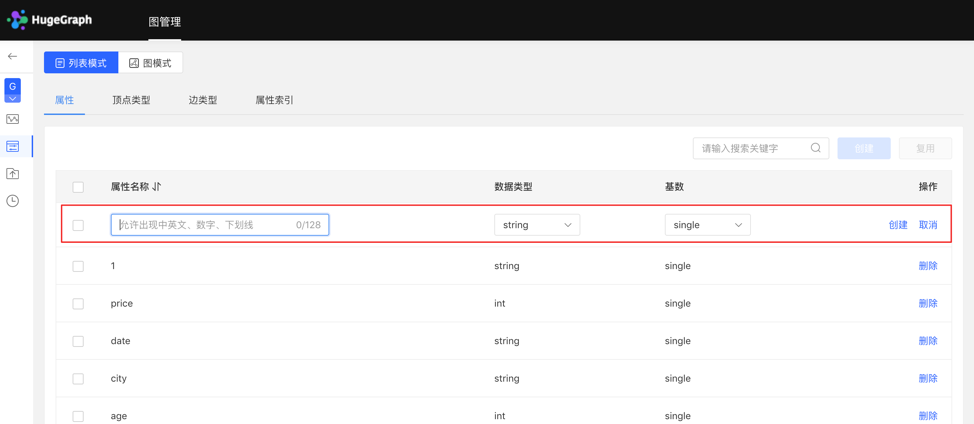
4.2.2.1 Create type
- Fill in or select the attribute name, data type, and cardinality to complete the creation of the attribute.
- Created attributes can be used as attributes of vertex type and edge type.
List mode:
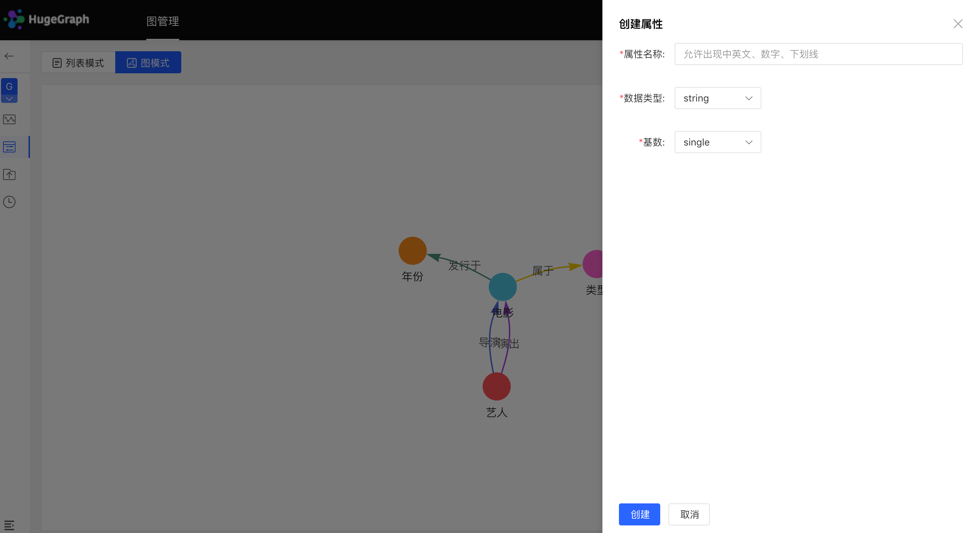
Graph mode:
4.2.2.2 Reuse
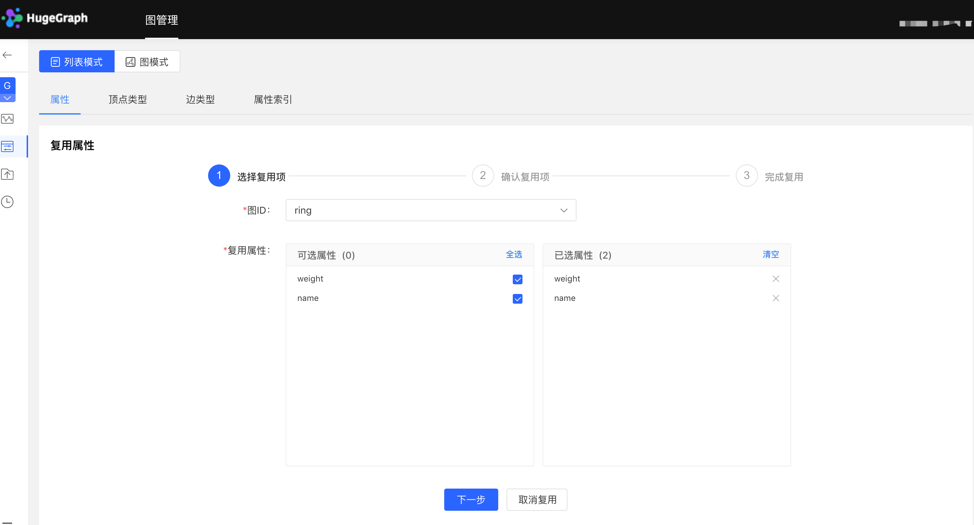
- The platform provides the [Reuse] function, which can directly reuse the metadata of other graphs.
- Select the graph ID that needs to be reused, and continue to select the attributes that need to be reused. After that, the platform will check whether there is a conflict. After passing, the metadata can be reused.
Select reuse items:
Check reuse items:
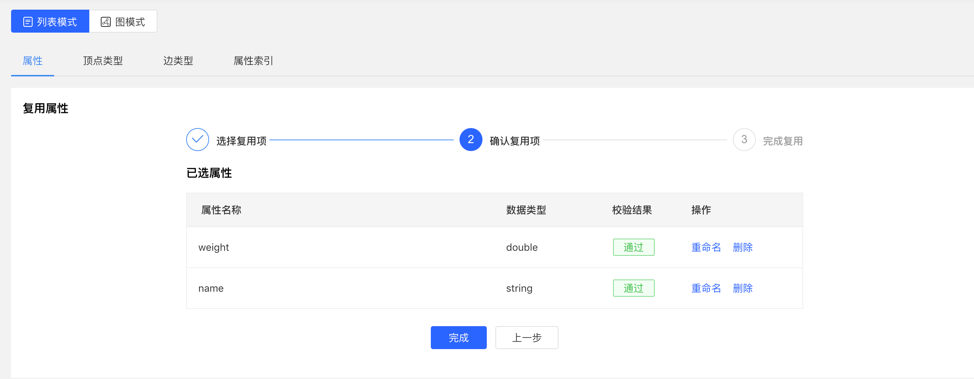
4.2.2.3 Management
- You can delete a single item or delete it in batches in the attribute list.
4.2.3 Vertex type
4.2.3.1 Create type
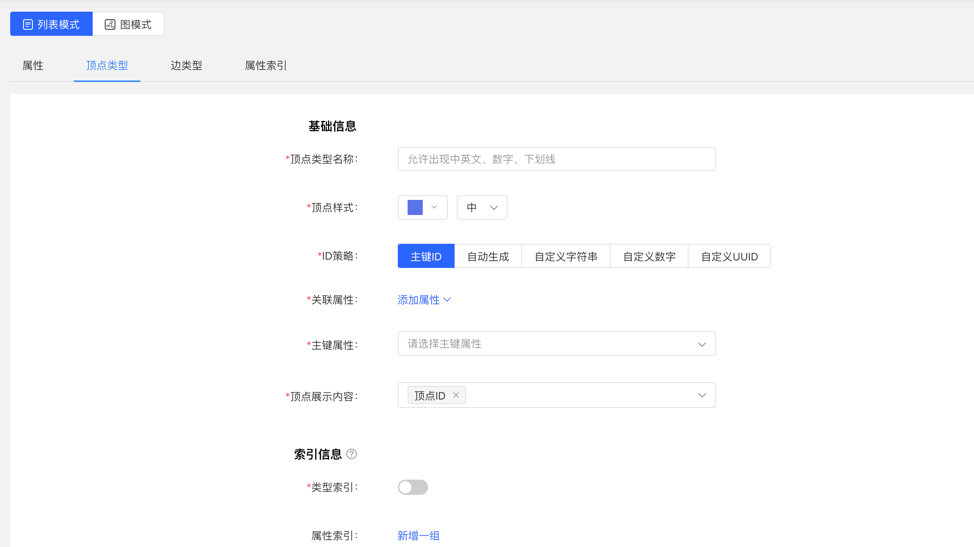
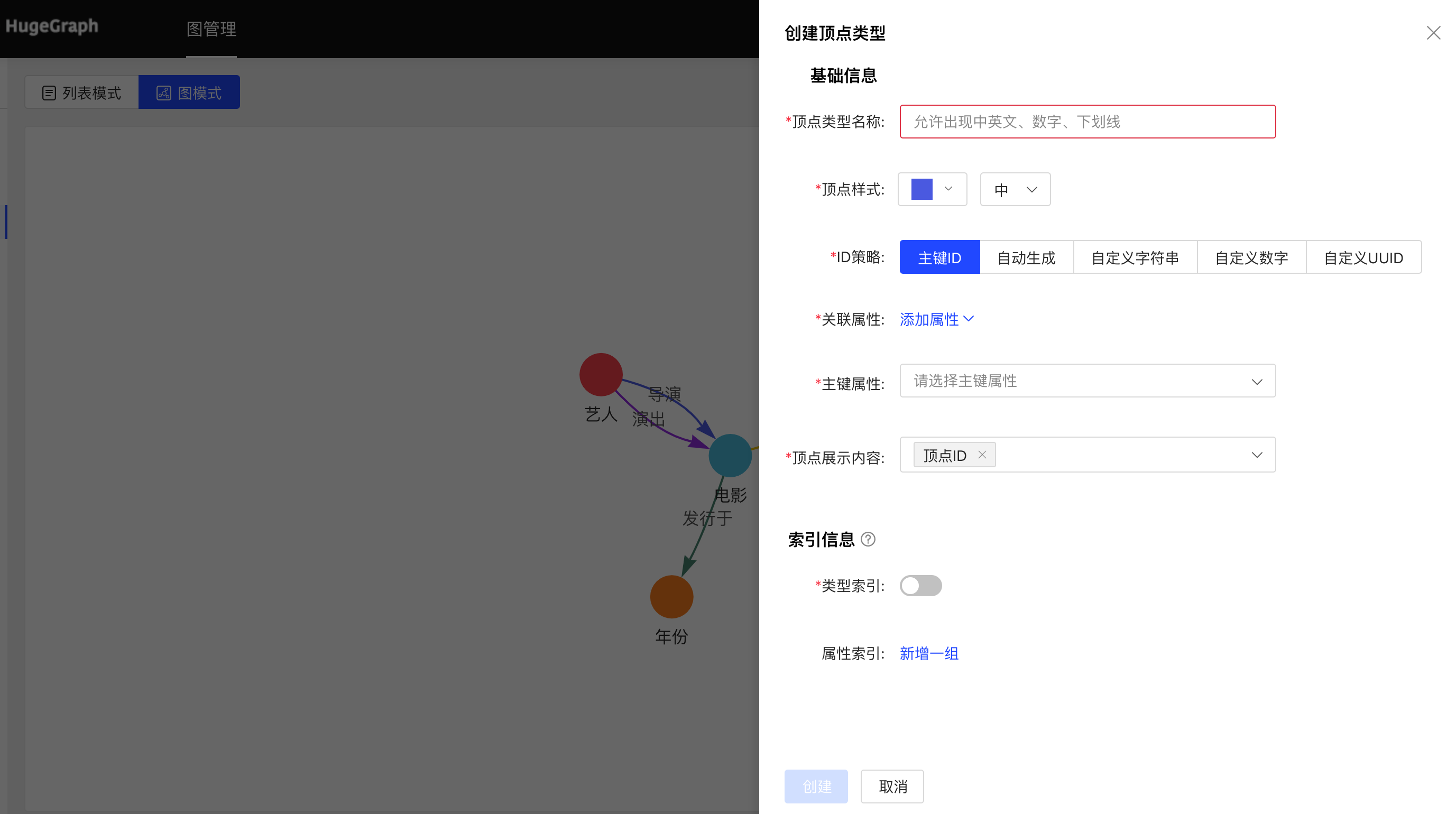
- Fill in or select the vertex type name, ID strategy, association attribute, primary key attribute, vertex style, content displayed below the vertex in the query result, and index information: including whether to create a type index, and the specific content of the attribute index, complete the vertex Type creation.
List mode:
Graph mode:
4.2.3.2 Reuse
- The multiplexing of vertex types will reuse the attributes and attribute indexes associated with this type together.
- The reuse method is similar to the property reuse, see 3.2.2.2.
4.2.3.3 Administration
Editing operations are available. The vertex style, association type, vertex display content, and attribute index can be edited, and the rest cannot be edited.
You can delete a single item or delete it in batches.
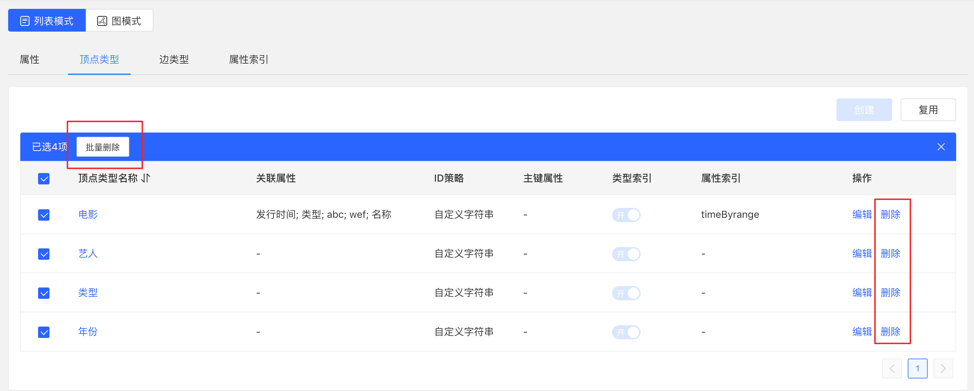
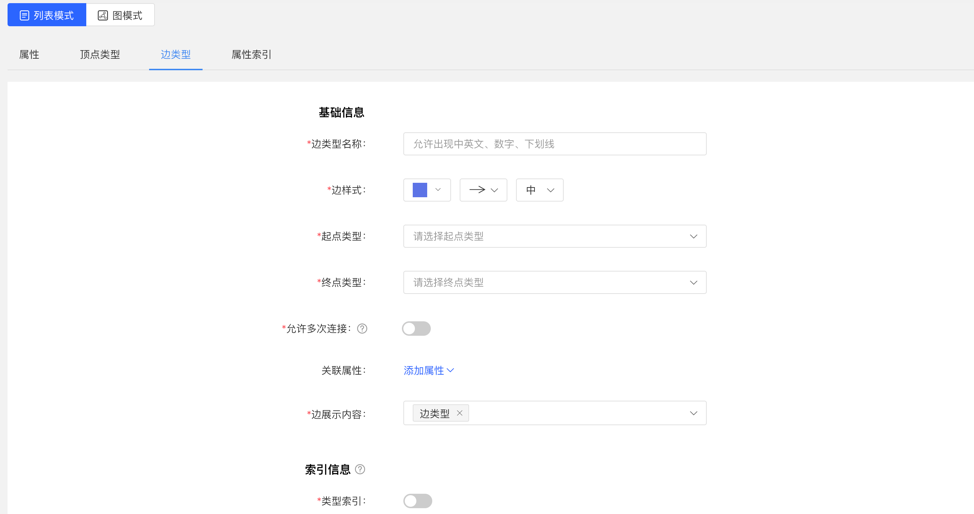
4.2.4 Edge Types
4.2.4.1 Create
- Fill in or select the edge type name, start point type, end point type, associated attributes, whether to allow multiple connections, edge style, content displayed below the edge in the query result, and index information: including whether to create a type index, and attribute index The specific content, complete the creation of the edge type.
List mode:
Graph mode:
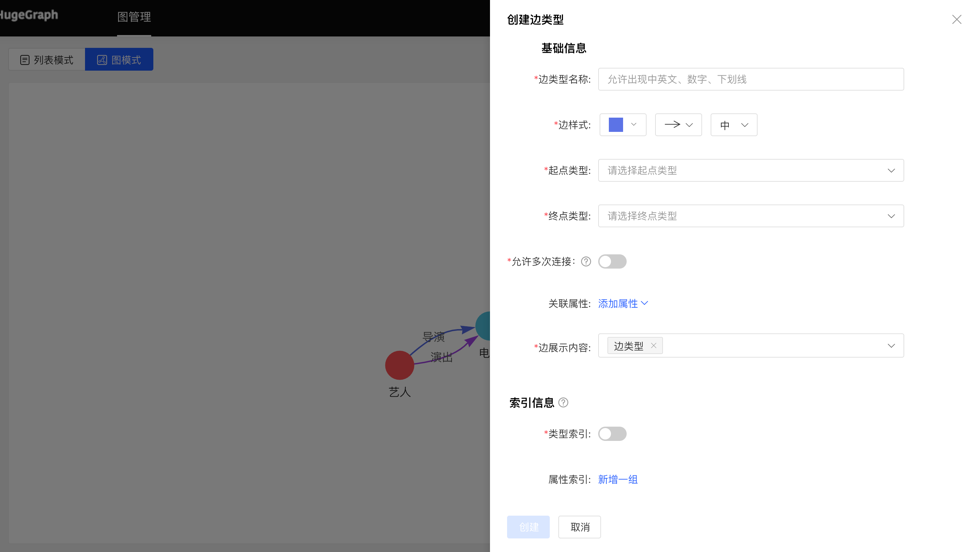
4.2.4.2 Reuse
- The reuse of the edge type will reuse the start point type, end point type, associated attribute and attribute index of this type.
- The reuse method is similar to the property reuse, see 3.2.2.2.
4.2.4.3 Administration
- Editing operations are available. Edge styles, associated attributes, edge display content, and attribute indexes can be edited, and the rest cannot be edited, the same as the vertex type.
- You can delete a single item or delete it in batches.
4.2.5 Index Types
Displays vertex and edge indices for vertex types and edge types.
4.3 Data Import
Note:currently, we recommend to use hugegraph-loader to import data formally. The built-in import of
hubbleis used for testing and getting started.
The usage process of data import is as follows:

4.3.1 Module entrance
Left navigation:
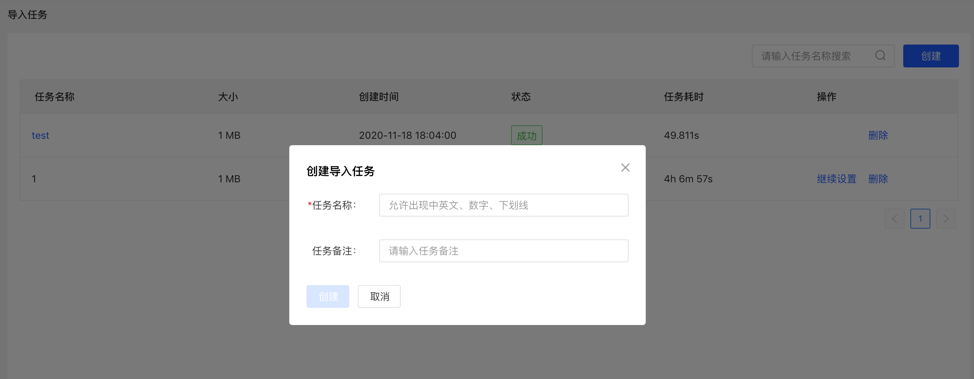
4.3.2 Create task
- Fill in the task name and remarks (optional) to create an import task.
- Multiple import tasks can be created and imported in parallel.
4.3.3 Uploading files
- Upload the file that needs to be composed. The currently supported format is CSV, which will be updated continuously in the future.
- Multiple files can be uploaded at the same time.
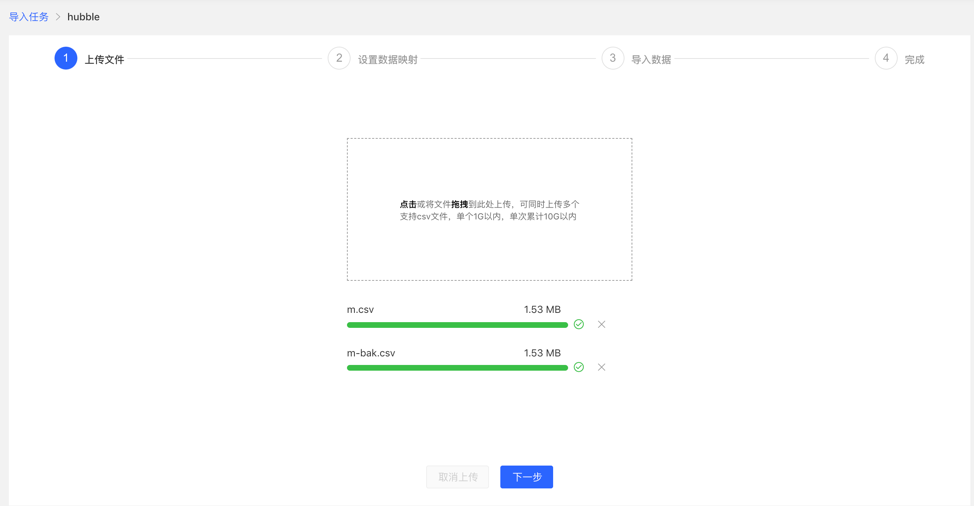
4.3.4 Setting up data mapping
Set up data mapping for uploaded files, including file settings and type settings
File settings: Check or fill in whether to include the header, separator, encoding format and other settings of the file itself, all set the default values, no need to fill in manually
Type setting:
Vertex map and edge map:
【Vertex Type】: Select the vertex type, and upload the column data in the file for its ID mapping;
【Edge Type】: Select the edge type and map the column data of the uploaded file to the ID column of its start point type and end point type;
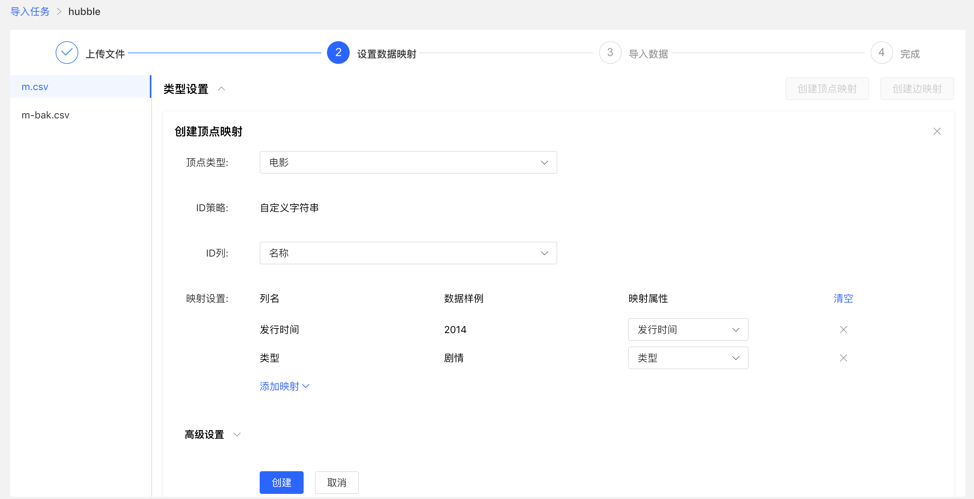
Mapping settings: upload the column data in the file for the attribute mapping of the selected vertex type. Here, if the attribute name is the same as the header name of the file, the mapping attribute can be automatically matched, and there is no need to manually fill in the selection.
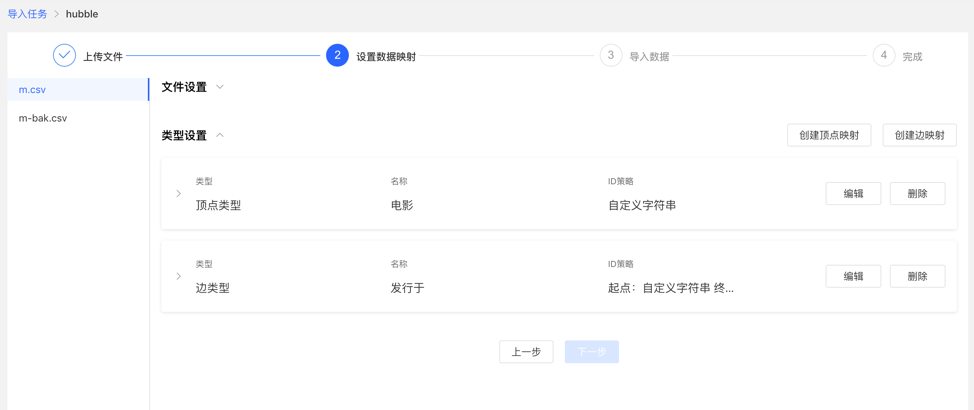
After completing the setting, the setting list will be displayed before proceeding to the next step. It supports the operations of adding, editing and deleting mappings.
Fill in the settings map:
Mapping list:
4.3.5 Import data
Before importing, you need to fill in the import setting parameters. After filling in, you can start importing data into the gallery.
- Import settings
- The import setting parameter items are as shown in the figure below, all set the default value, no need to fill in manually
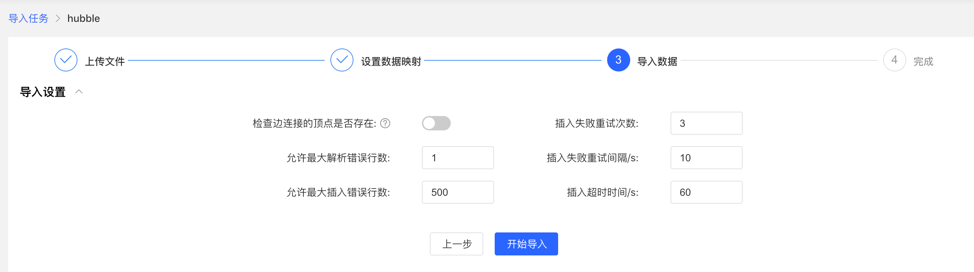
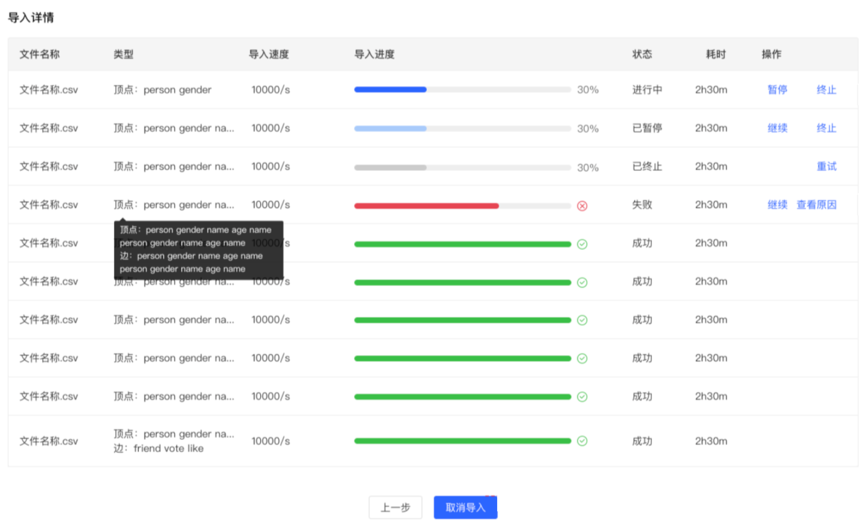
- Import details
- Click Start Import to start the file import task
- The import details provide the mapping type, import speed, import progress, time-consuming and the specific status of the current task set for each uploaded file, and can pause, resume, stop and other operations for each task
- If the import fails, you can view the specific reason
4.4 Data Analysis
4.4.1 Module entry
Left navigation:
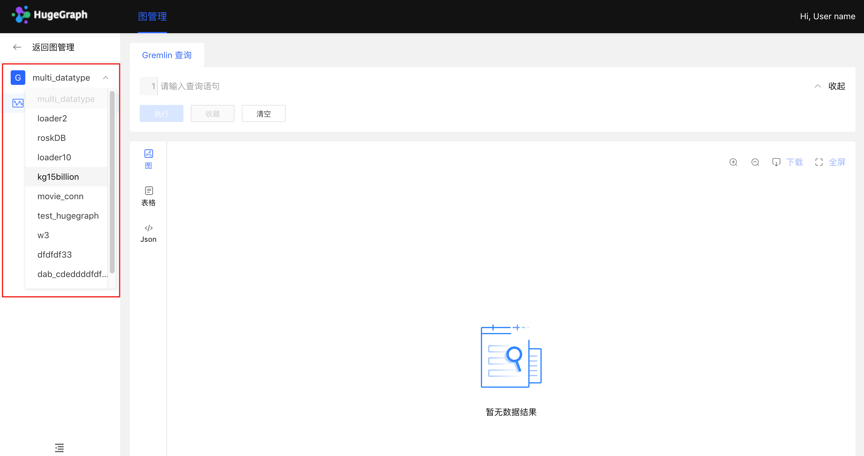
4.4.2 Multi-graphs switching
By switching the entrance on the left, flexibly switch the operation space of multiple graphs
4.4.3 Graph Analysis and Processing
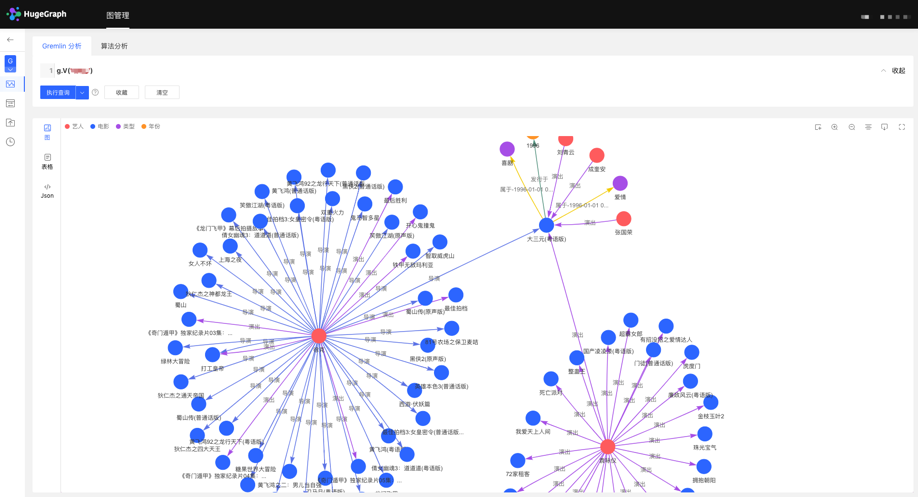
HugeGraph supports Gremlin, a graph traversal query language of Apache TinkerPop3. Gremlin is a general graph database query language. By entering Gremlin statements and clicking execute, you can perform query and analysis operations on graph data, and create and delete vertices/edges. vertex/edge attribute modification, etc.
After Gremlin query, below is the graph result display area, which provides 3 kinds of graph result display modes: [Graph Mode], [Table Mode], [Json Mode].
Support zoom, center, full screen, export and other operations.
【Picture Mode】
【Table mode】
【Json mode】

4.4.4 Data Details
Click the vertex/edge entity to view the data details of the vertex/edge, including vertex/edge type, vertex ID, attribute and corresponding value, expand the information display dimension of the graph, and improve the usability.
4.4.5 Multidimensional Path Query of Graph Results
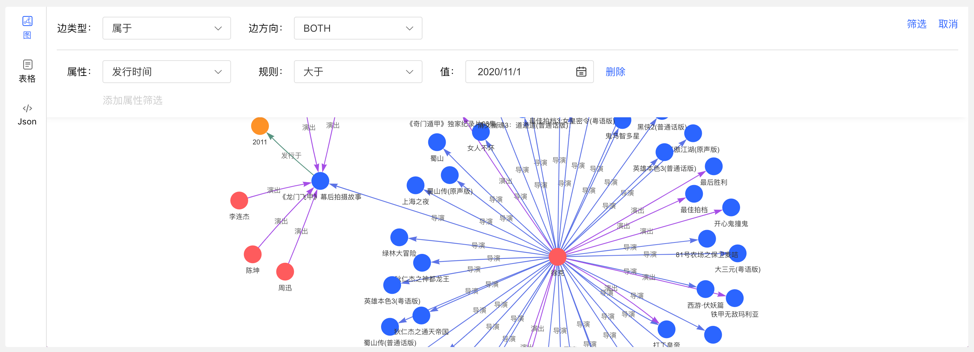
In addition to the global query, an in-depth customized query and hidden operations can be performed for the vertices in the query result to realize customized mining of graph results.
Right-click a vertex, and the menu entry of the vertex appears, which can be displayed, inquired, hidden, etc.
- Expand: Click to display the vertices associated with the selected point.
- Query: By selecting the edge type and edge direction associated with the selected point, and then selecting its attributes and corresponding filtering rules under this condition, a customized path display can be realized.
- Hide: When clicked, hides the selected point and its associated edges.
Double-clicking a vertex also displays the vertex associated with the selected point.
4.4.6 Add vertex/edge
4.4.6.1 Added vertex
In the graph area, two entries can be used to dynamically add vertices, as follows:
- Click on the graph area panel, the Add Vertex entry appears
- Click the first icon in the action bar in the upper right corner
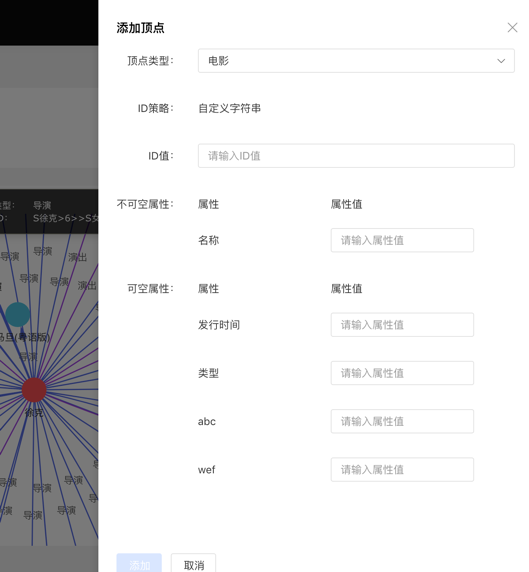
Complete the addition of vertices by selecting or filling in the vertex type, ID value, and attribute information.
The entry is as follows:
Add the vertex content as follows:
4.4.6.2 Add edge
Right-click a vertex in the graph result to add the outgoing or incoming edge of that point.
4.4.7 Execute the query of records and favorites
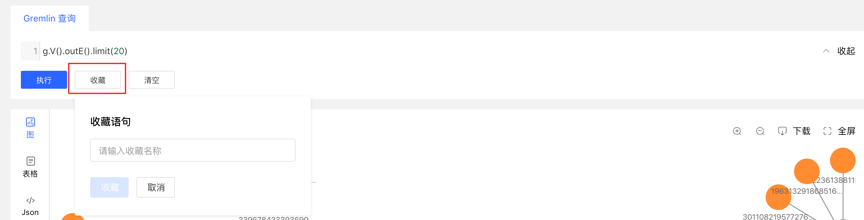
- Record each query record at the bottom of the graph area, including: query time, execution type, content, status, time-consuming, as well as [collection] and [load] operations, to achieve a comprehensive record of graph execution, with traces to follow, and Can quickly load and reuse execution content
- Provides the function of collecting sentences, which can be used to collect frequently used sentences, which is convenient for fast calling of high-frequency sentences.
4.5 Task Management
4.5.1 Module entry
Left navigation:
4.5.2 Task Management
- Provide unified management and result viewing of asynchronous tasks. There are 4 types of asynchronous tasks, namely:
- gremlin: Gremlin tasks
- algorithm: OLAP algorithm task
- remove_schema: remove metadata
- rebuild_index: rebuild the index
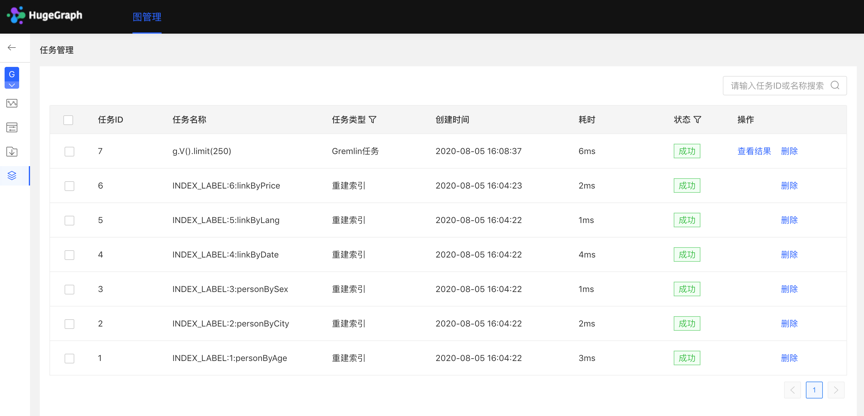
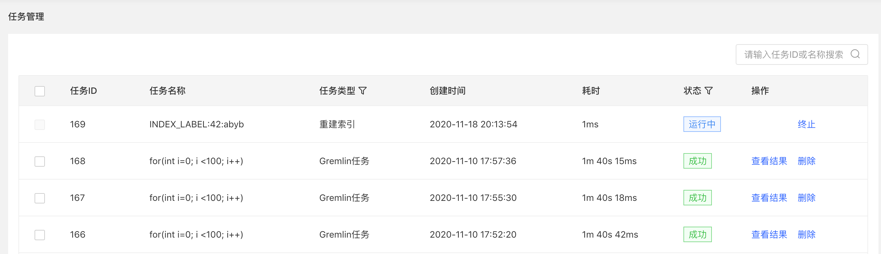
- The list displays the asynchronous task information of the current graph, including task ID, task name, task type, creation time, time-consuming, status, operation, and realizes the management of asynchronous tasks.
- Support filtering by task type and status
- Support searching for task ID and task name
- Asynchronous tasks can be deleted or deleted in batches
4.5.3 Gremlin asynchronous tasks
- Create a task
- The data analysis module currently supports two Gremlin operations, Gremlin query and Gremlin task; if the user switches to the Gremlin task, after clicking execute, an asynchronous task will be created in the asynchronous task center;
- Task submission
- After the task is submitted successfully, the graph area returns the submission result and task ID
- Mission details
- Provide [View] entry, you can jump to the task details to view the specific execution of the current task After jumping to the task center, the currently executing task line will be displayed directly
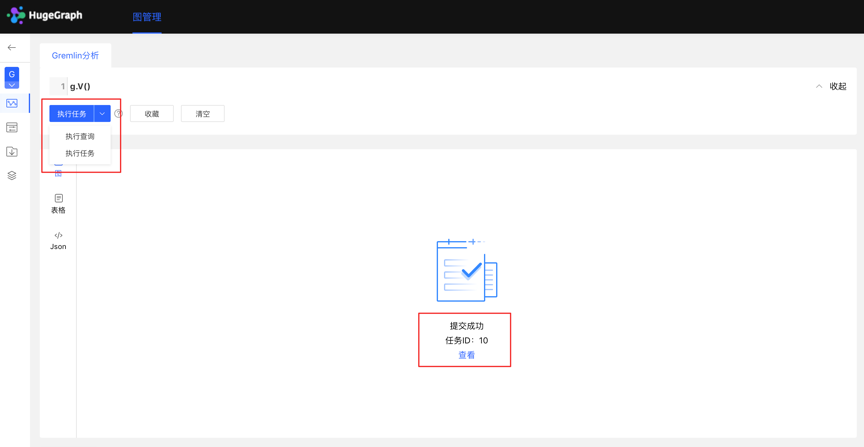
Click to view the entry to jump to the task management list, as follows:
- View the results
- The results are displayed in the form of JSON
4.5.4 OLAP algorithm tasks
There is no visual OLAP algorithm execution on Hubble. You can call the RESTful API to perform OLAP algorithm tasks, find the corresponding tasks by ID in the task management, and view the progress and results.
4.5.5 Delete metadata, rebuild index
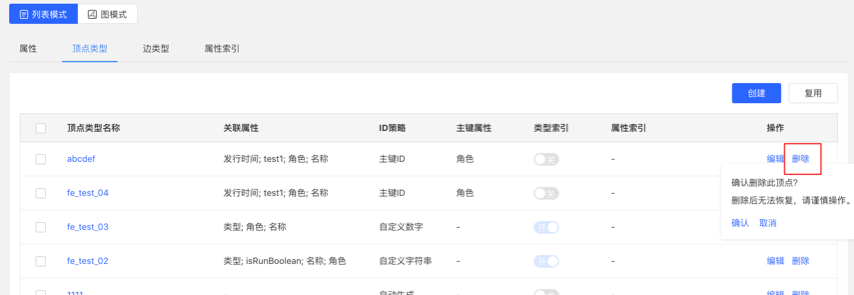
- Create a task
- In the metadata modeling module, when deleting metadata, an asynchronous task for deleting metadata can be created
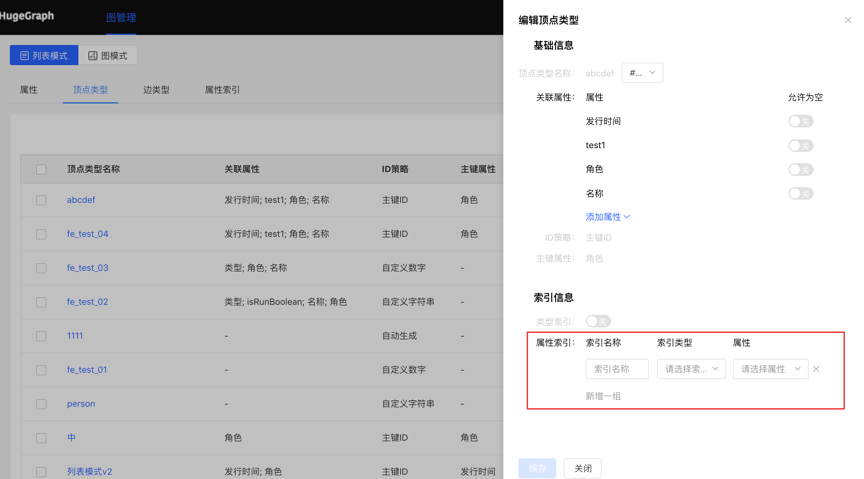
- When editing an existing vertex/edge type operation, when adding an index, an asynchronous task of creating an index can be created
- Task details
- After confirming/saving, you can jump to the task center to view the details of the current task